
随着AI大模型从云端向端侧加速落地,如何在有限算力的终端设备上高效运行多模态模型,成为AIoT产业落地的关键挑战。在此背景下,瑞芯微电子(Rockchip)正式发布的RK1820/RK1828 AI协处理器RKNN3 SDK V1.0.0,被视为其在端侧AI生态布局中的重要一步。这一举措不仅标志着其软件工具链的成熟度迈上新台阶,更体现了瑞芯微在“后摩尔定律”时代,通过软硬件深度协同来突破算力瓶颈的战略意图。
 该SDK旨在适配RK3588/RK3576主控芯片与RK182X协处理器的硬件组合,为端侧AI模型部署提供全栈式软件支持。从行业视角来看,此次更新不仅是技术参数的迭代,更是瑞芯微针对“感知-决策-执行”闭环能力的一次系统性强化。在当前激烈的边缘计算市场竞争中,单纯的硬件算力堆砌已无法满足市场需求,只有通过SDK等软件层面对硬件进行“打磨”,才能真正释放芯片的潜能,这也是瑞芯微此次发布的核心价值所在。
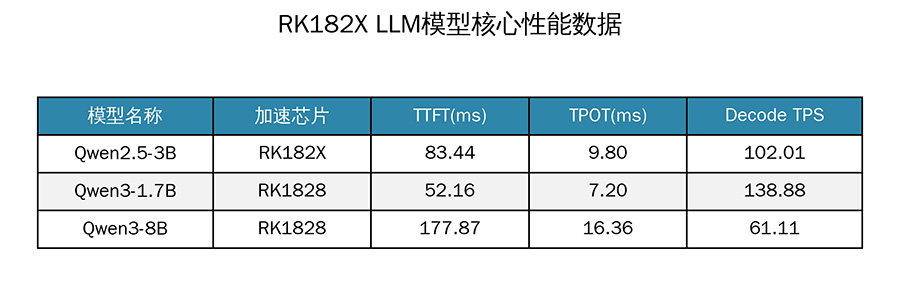
该SDK旨在适配RK3588/RK3576主控芯片与RK182X协处理器的硬件组合,为端侧AI模型部署提供全栈式软件支持。从行业视角来看,此次更新不仅是技术参数的迭代,更是瑞芯微针对“感知-决策-执行”闭环能力的一次系统性强化。在当前激烈的边缘计算市场竞争中,单纯的硬件算力堆砌已无法满足市场需求,只有通过SDK等软件层面对硬件进行“打磨”,才能真正释放芯片的潜能,这也是瑞芯微此次发布的核心价值所在。在性能层面,新SDK实现了LLM(大语言模型)解码效率整体提升超15%,并对0.5B至8B不同参数量级的模型完成深度适配。例如,Qwen2.5-3B模型的Decode TPS突破100,Qwen2.5-0.5B模型的首Token延迟(TTFT)低至21.89ms,这些指标为端侧实时交互提供了技术基础。对于中大型模型,Qwen3-8B在RK1828上亦实现了稳定推理。这种性能的提升,意味着开发者可以在更低功耗的设备上部署更复杂的对话系统,从而拓展了智能家居、便携式翻译机等消费电子产品的功能边界。
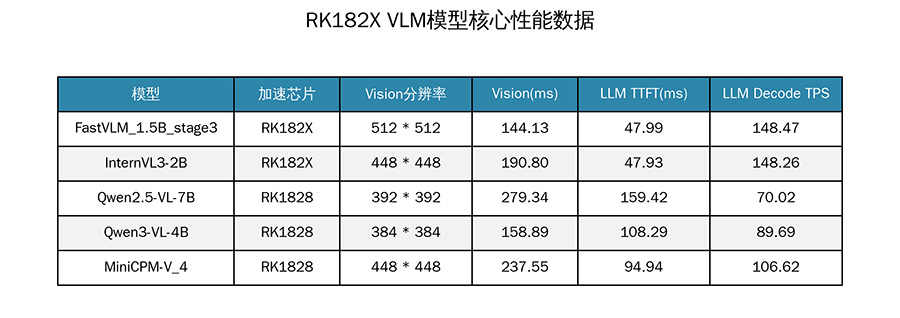
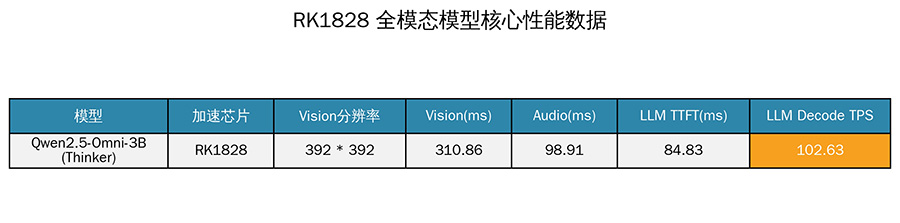 在多模态支持方面,RK182X对Qwen3-VL系列模型提供了完整适配,其中Qwen3-VL-4B的LLM Decode TPS接近90TPS。此外,RK1828还支持Qwen2.5-Omni-3B全模态模型,实现了音视觉与语言的全链路高效推理,解码TPS达102.63。这一能力的实现,标志着端侧AI正从单一的语音或视觉识别,向更复杂的跨模态理解演进,为智能眼镜、机器人等需要综合环境感知能力的设备提供了强有力的技术支撑。
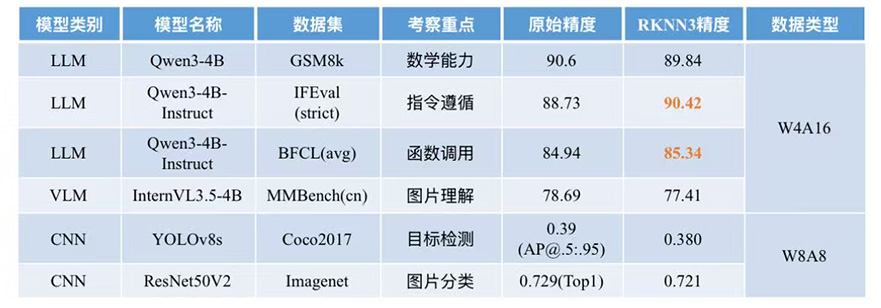
在多模态支持方面,RK182X对Qwen3-VL系列模型提供了完整适配,其中Qwen3-VL-4B的LLM Decode TPS接近90TPS。此外,RK1828还支持Qwen2.5-Omni-3B全模态模型,实现了音视觉与语言的全链路高效推理,解码TPS达102.63。这一能力的实现,标志着端侧AI正从单一的语音或视觉识别,向更复杂的跨模态理解演进,为智能眼镜、机器人等需要综合环境感知能力的设备提供了强有力的技术支撑。在生态构建上,瑞芯微通过差异化量化策略,在提升推理性能的同时有效控制精度损失。其量化后模型精度与原始float32版本基本持平,部分模型甚至实现精度反超。这种对模型精度的严格把控,解决了开发者在部署过程中“性能与精度不可兼得”的痛点。此外,SDK兼容Hugging Face、ModelScope等主流开源平台,开发者可直接从GitHub获取预转换的RKNN模型,降低开发门槛。这种开放的姿态有助于吸引全球开发者加入其生态系统,形成良性循环。
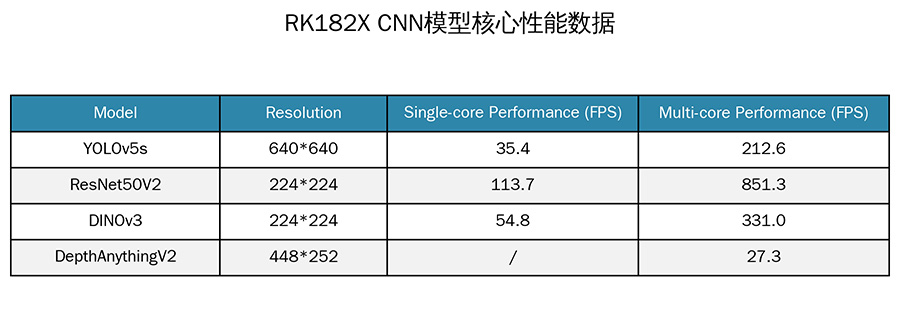
 从行业趋势来看,此次SDK的发布紧扣AIoT 2.0的发展需求。在感知层,其适配了Mobilenet、YOLO系列视觉模型,并与科大讯飞、思必驰等厂商合作完成语音模型适配;在决策层,覆盖了Qwen3-VL、GLM Edge等主流开源大模型,并深度适配智谱MiniCPM等头部厂商模型;在执行层,支持协处理器自定义后处理,实现从算法到应用的转化。这种全方位的布局,使得瑞芯微不仅仅是一个芯片供应商,更逐渐演变为一个端侧AI解决方案的赋能者。
从行业趋势来看,此次SDK的发布紧扣AIoT 2.0的发展需求。在感知层,其适配了Mobilenet、YOLO系列视觉模型,并与科大讯飞、思必驰等厂商合作完成语音模型适配;在决策层,覆盖了Qwen3-VL、GLM Edge等主流开源大模型,并深度适配智谱MiniCPM等头部厂商模型;在执行层,支持协处理器自定义后处理,实现从算法到应用的转化。这种全方位的布局,使得瑞芯微不仅仅是一个芯片供应商,更逐渐演变为一个端侧AI解决方案的赋能者。随着端侧AI应用场景的不断丰富,软硬件协同优化能力正成为厂商竞争的关键。瑞芯微此次通过SDK的系统性更新,进一步夯实了其在端侧AI协处理领域的技术积累,也为智能硬件、工业检测等多元场景的AI落地提供了新的解决方案。未来,随着更多开发者基于该SDK开发出创新应用,瑞芯微在端侧AI市场的护城河也将进一步加深。
Model Zoo地址: https://github.com/airockchip/rknn3-model-zoo 工具提取地址: https://github.com/airockchip/rknn3-toolkit











