
复盘RKDC2025瑞芯微开发者大会,若要给这场开发者大会找一个“第一性”总结,我会把票投给一句话——面向端侧大模型的贡嘎系列协处理器是 RKDC2025 的最大亮点。

为什么不是 RK3688、RK3668,也不是 RK2116 或 RV1126B?原因并不复杂:
-
RK2116 定位纯音频场景,虽与 AIGC 语音交互有关,但终究只是“听”和“说”;
-
RV1126B 已进入量产落地,去年就出现在智能摄像机、边缘盒子中,RKDC2025 更多是“秀肌肉”,对当下业务的增量影响不大;
-
RK3688 / RK3668 官方明确“短时间不会面世”,SoC 级大迭代节奏注定以年为单位;
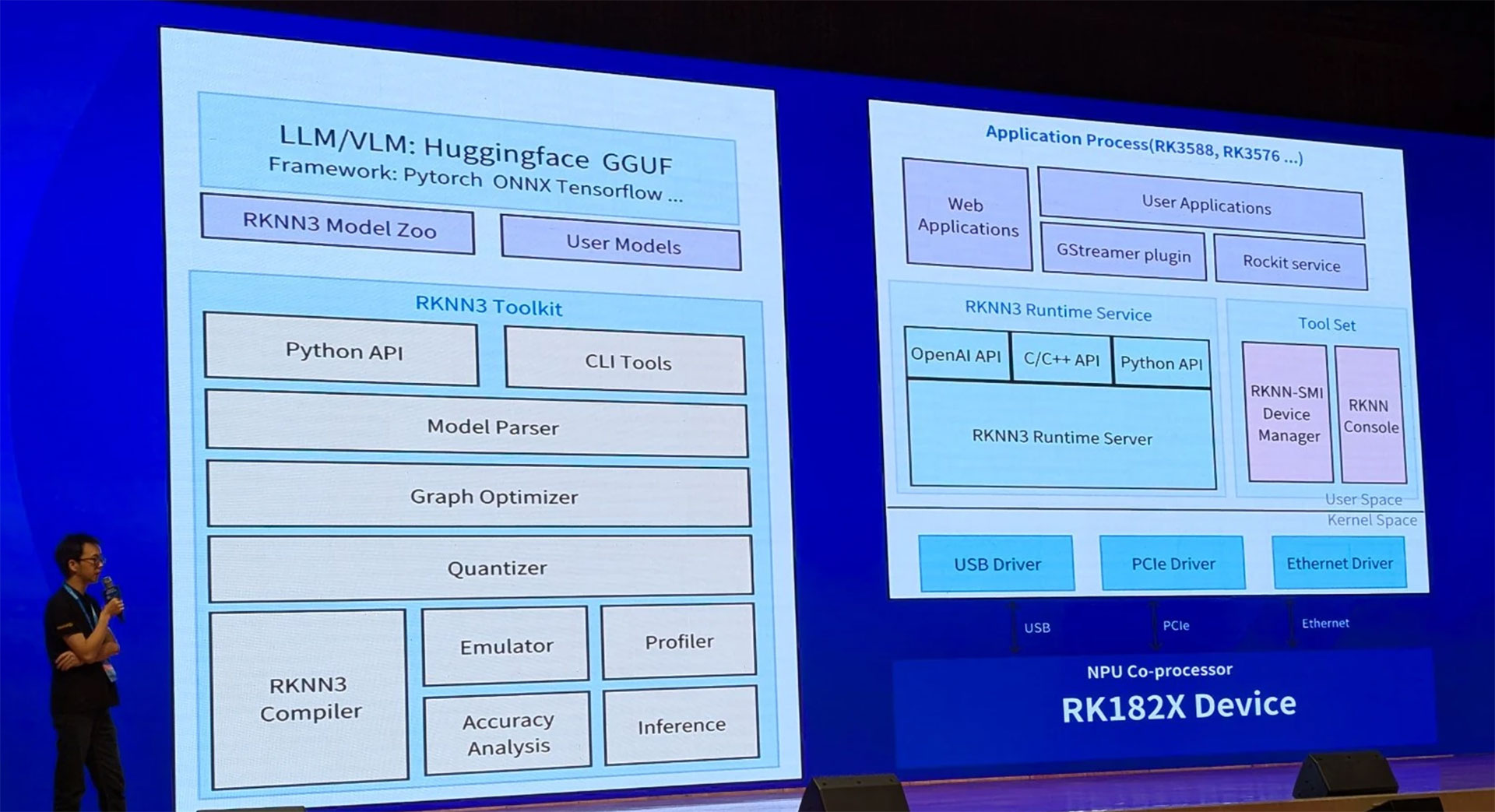
因此,本文把焦点锁定在贡嘎系列,结合 RKDC2025 公开的三张技术图片,拆解 RK1820 / 1828 的参数与性能,并回答一个核心问题:它们为什么对端侧大模型如此重要?
一、从“存力、运力、算力”到“百 token 级端侧推理”
RKDC2025 keynote 把贡嘎系列的设计哲学总结为 “存力-运力-算力”三位一体,其关键性能如下:
| 维度 | RK1820 | RK1828 | 对端侧大模型的意义 |
|---|---|---|---|
| 存力 | 2.5 GB DDR 合封 | 5 GB DDR 合封 | 足够放下 3B / 7B 量化模型(W4A16 仅 1.5 GB / 3.5 GB 左右),且无需外挂 DRAM,节省 PCB 面积与功耗 |
| 运力 | 百 GB/s 级片上带宽 | 同上 | 让 3B/7B 模型在 1.2 GHz NPU 上跑出 100+ token/s 的 decode 速度,避免“算力等数据” |
| 算力 | 1.2 GHz NPU(≈8 TOPS INT8) | 同上 | 支撑 Qwen2.5-1.5B/3B/7B、DeepSeek-R1-Distill-Qwen-7B 等主流开源模型,单帧延迟 < 0.1 s |
关键词:合封 DRAM。传统方案“CPU + 外挂 LPDDR”在 7B 级模型面前,要么带宽不足,要么功耗爆炸。贡嘎系列用 3D 合封把 DRAM 拉到芯片内部,等于用封装技术把“内存墙”拆了一截,这是它与以往 RK NPU 最大的代际差异。
二、性能实测:数字说话
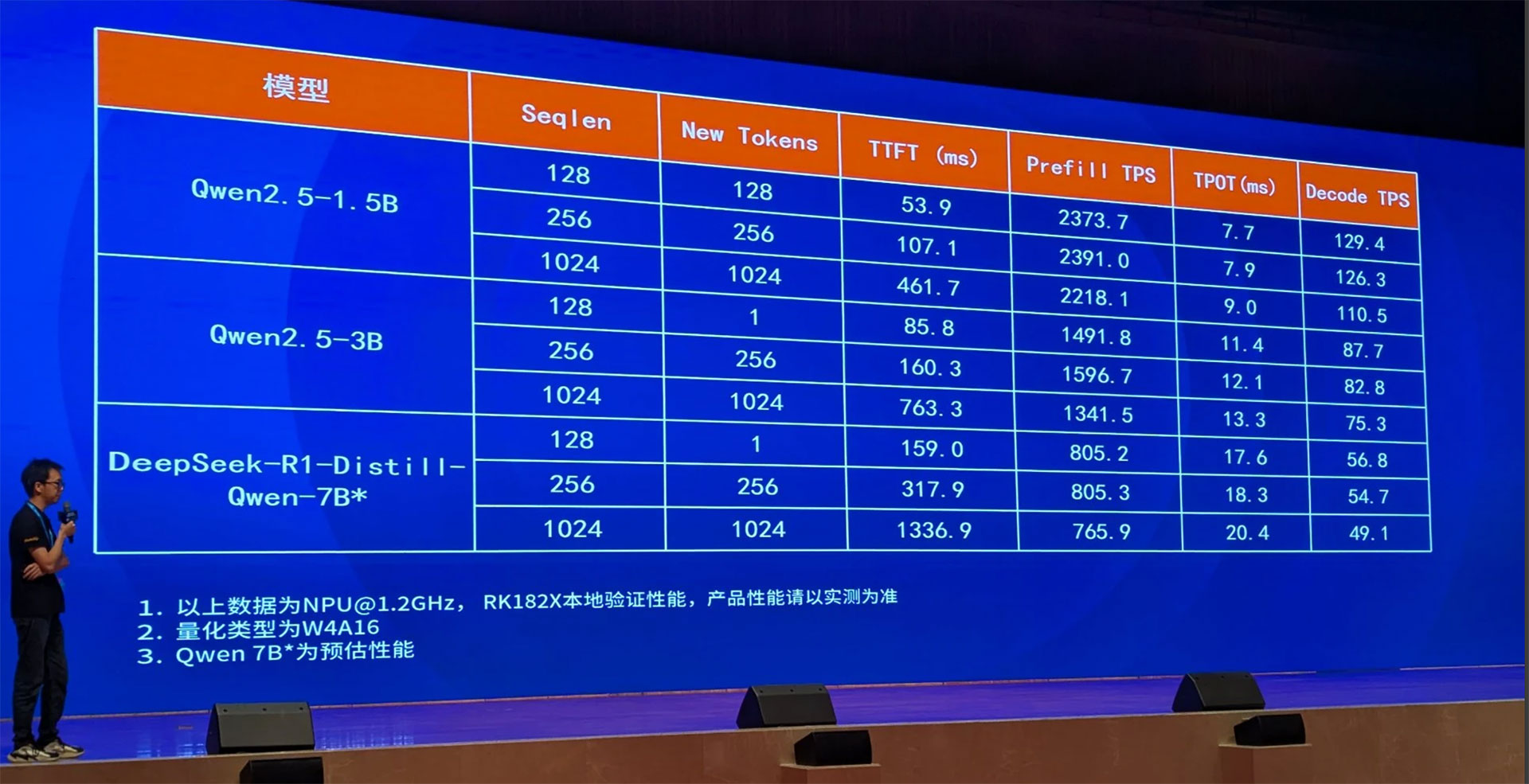
瑞芯微官方给出了 NPU@1.2 GHz、W4A16 量化下的实测或预估值:
| 模型 | 输入 | TTFT (ms) | Decode TPOT (ms) | Decode TPS |
|---|---|---|---|---|
| Qwen2.5-1.5B | 128 token | 53.9 | 7.7 | 129.4 |
| Qwen2.5-3B | 256 token | 85.8 | 11.4 | 87.7 |
| DeepSeek-R1-Distill-Qwen-7B | 256 token | 159.0 | 18.3 | 54.7 |
解读:
-
TTFT(Time To First Token) 代表“用户按下回车到看到第一个字”的等待时间,100~200 ms 以内人类几乎无感;
-
TPOT(Time Per Output Token) 决定“打字机式输出”的流畅度,20 ms 以内即可做到“秒回”;
-
TPS(Token Per Second) 是最直观的吞吐指标,RK1828 在 7B 模型上还能逼近 50 token/s,已经追平甚至超越不少云端 4 vCPU 轻量实例。
这些数字全部在端侧、离线、无风扇条件下测得,相当于把“GPT-3.5 级别”的对话体验塞进了一块邮票大小的芯片里。
三、为什么“协处理器”而不是“大 SoC”?
贡嘎系列把 CPU 做成配角,NPU 做主角,官方称之为 “AI Co-processor”。这样做带来三大好处:
-
兼容存量主控:RK3588、RK3576 乃至第三方 ARM/x86 平台,只需通过 USB/PCIe/Ethernet 把贡嘎当作“外挂算力卡”,无需重写 BSP。
-
功耗分区:主控跑 OS、UI,贡嘎跑大模型,二者独立 DVFS,整机 idle 功耗可低到一个数量级。
-
迭代节奏解耦:CPU 升级跟着 Android LTS,NPU 升级跟着模型演进,互不影响。
一句话总结:贡嘎系列让“大模型”成为可插拔模块,而不是强迫整机厂换主控、换板型、重新认证。
四、落地场景:从“Demo”到“量产”
RKDC2025 展区里最不缺的就是贡嘎盒子:
-
教育平板:离线 7B 老师,断网也能讲题;
-
工业头盔:本地知识库 + 语音问答,工厂 Wi-Fi 死角无压力;
-
车载座舱:10 路以上并发语音 Agent,无需把车内谈话上传云端;
-
家庭机器人:3B 模型跑情感陪伴,5 W 功耗比 X86 小主机低一个数量级。
这些场景的共同点是:隐私敏感、网络不稳、功耗苛刻,恰好是端侧大模型的“甜蜜点”。
五、未来展望
从Gongga1的编号就可以看出,有“1”就有“2”,这将是一个长期的产品线。据Rockchip 官方透露,RK182X 的后续版本将支持 13B 模型(通过双芯级联)与 4K 长视频理解,同时开放片上 SRAM 做 KV-Cache 缓存,目标在 2026 年实现“百元级模组跑 13B”。随着 RKNN3.0 的开源社区逐步壮大,RK182X 有望成为端侧大模型时代的“386 时刻”——把原本云端昂贵的 AI 能力,真正普及到每一台边缘设备。
结语:贡嘎系列是 RKDC2025 的“现在进行时”
回到文章开头,为什么贡嘎系列是最大亮点?因为它把“大模型上端侧”从 PPT 变成了 BOM 表里的可采购料号;把“存算一体”从论文变成了可量产的 2.5 GB/5 GB 合封 DRAM;把“百 token/s”从实验室数据变成了开发者大会观众现场体验到的打字机式输出。
RK3688、RK3668 再惊艳,也只是“未来”;RV2116、RV1126B 再成熟,也只是“过去”。唯有贡嘎系列,定义了瑞芯微在 2025 年下半年的“现在进行时”。
如果你正在做需要离线大模型的产品,不妨把贡嘎系列加入 BOM,因为它可能是近一年内唯一真正“买得到、用得起、跑得动 7B”的端侧 AI 答案。











