
一句话看懂贡嘎:它不是一块普通的AI芯片,而是瑞芯微为旗舰SoC(RK3576/RK3588)量身定制的“大模型专用外挂”,让手机、机器人、车载终端等设备无需联网就能跑3B/7B参数的大模型,速度100tokens/s,延迟仅0.1秒。
一、为什么需要贡嘎?——端侧大模型的三大痛点
| 痛点 | 传统方案 | 贡嘎的解决方式 |
|---|---|---|
| 算力不足 | 手机NPU算力仅1-3T,跑7B模型像“小马拉大车” | 独立协处理器,单芯片6-50T算力灵活扩展 |
| 内存瓶颈 | SoC内存需兼顾系统和AI,大模型上下文被压缩到2K | 2.5GB/5GB独立高带宽DRAM,支持16K上下文 |
| 延迟过高 | 云端推理往返需1-3秒,实时对话卡顿 | 端到端延迟0.1秒,本地推理零等待 |
二、技术解剖:贡嘎的四大黑科技
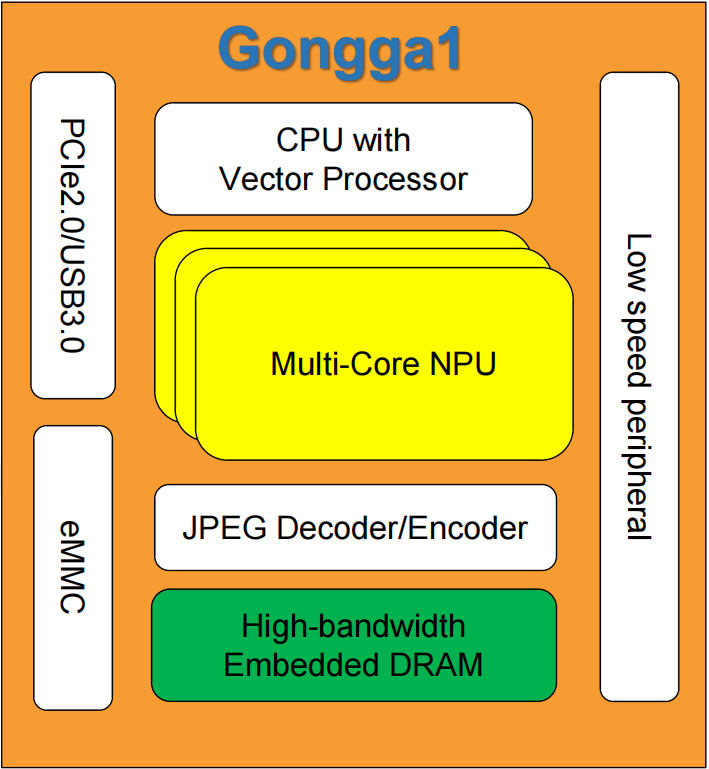 1. 先进封装:把“内存墙”拆了
1. 先进封装:把“内存墙”拆了
-
2.5D/3D堆叠技术:将5GB嵌入式DRAM与NPU封装在一起,带宽提升10倍,彻底消除数据搬运瓶颈。
-
案例:跑7B参数的大模型时,传统方案需频繁读写外部DDR,功耗飙升;贡嘎片内内存让数据“就地计算”,功耗降低60%。
2. 混合计算架构:CPU+NPU的“双引擎”
-
RISC-V主控:128位矢量扩展,负责数据预处理(如分词、语音特征提取)。
-
多核NPU:支持INT8(高精度)和W4A16(超低比特)混合计算,动态切换:
-
对话场景:W4A16模式,速度优先(100tokens/s);
-
视觉场景:INT8模式,精度优先(支持4K JPEG实时编解码)。
-
3. 超低延迟流水线:0.1秒的秘密
-
三级优化:
-
指令预取:CPU提前加载下一条推理指令;
-
权重缓存:7B模型权重常驻片内内存,无需重复加载;
-
并行解码:NPU同时计算50个token,传统方案逐一生成。
-
4. 多模态原生支持:语音/图片/视频“一网打尽”
-
统一接口:开发者调用同一套API(兼容OpenAI格式)即可实现:
-
语音:中英文混合语音识别(如“帮我订一张北京到上海的票”);
-
视觉:4K摄像头实时目标检测(如车载场景识别行人、交通标志);
-
视频:本地视频内容摘要(如自动生成1分钟电影解说)。
-
三、实战场景:贡嘎如何改变终端设备?
 场景1:车载多模态助手
场景1:车载多模态助手

-
硬件组合:RK3588(主控)+ 2×贡嘎(双协处理器)
-
功能演示:
-
语音交互:司机说“我饿了”,系统本地分析语义→推荐附近餐厅(0.3秒响应,无需联网);
-
视觉感知:4K摄像头实时检测前车急刹,触发自动紧急制动(延迟<50ms)。
-
场景2:教育机器人
-
硬件组合:RK3576(主控)+ 1×贡嘎(5GB版)
-
功能演示:
-
离线辅导:小学生用语音提问“恐龙是怎么灭绝的?”,机器人本地调用7B教育模型生成动画解说(100tokens/s流畅输出);
-
手势互动:摄像头识别学生手势(如举手、OK),触发对应教学模块。
-
场景3:安防摄像头
-
硬件组合:RK3588 + 4×贡嘎(边缘服务器)
-
功能演示:
-
行为分析:本地识别“人员跌倒”“非法闯入”等异常行为,仅上传告警片段(节省90%流量);
-
口罩检测:INT8模式高精度识别,误报率<0.1%。
-
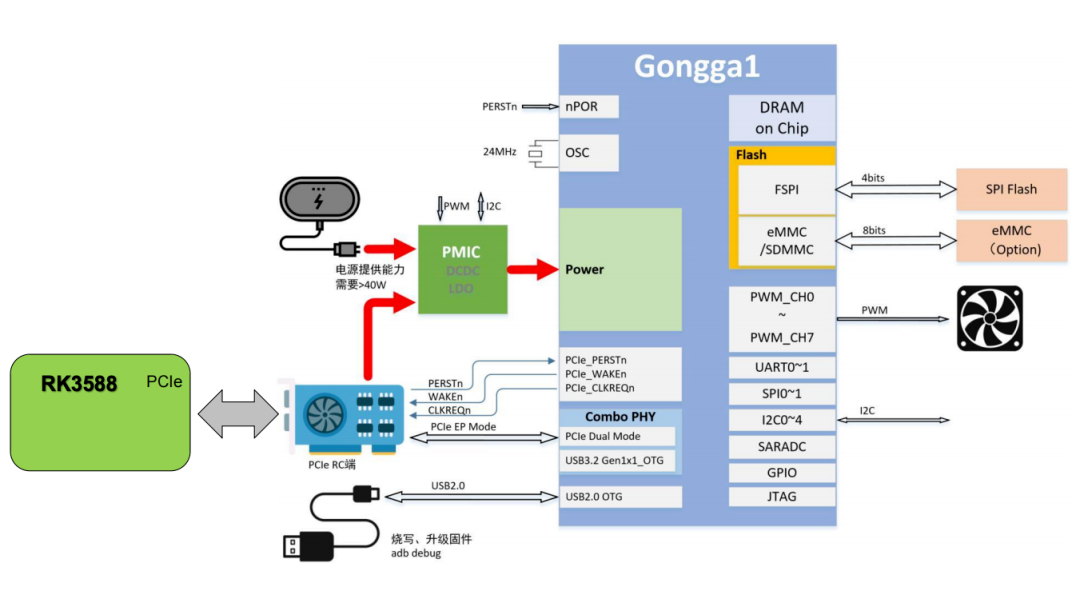
四、开发者指南:如何快速上手贡嘎?
1. 模型迁移三步走
| 步骤 | 工具 | 示例 |
|---|---|---|
| 转换 | 瑞芯微RKNN Toolkit | 将Huggingface的Llama-7B转为W4A16格式 |
| 优化 | 自动量化工具 | 对CNN模型剪枝+量化,体积缩小80% |
| 部署 | OpenAI兼容API | import gongga; gongga.chat("你好") |
2. 硬件选型建议
| 终端类型 | 推荐配置 | 典型算力 |
|---|---|---|
| 智能耳机 | RK3576 + 1×贡嘎(2.5GB) | 6T,支持离线语音翻译 |
| 家用机器人 | RK3588 + 2×贡嘎(5GB) | 12T,跑7B模型+4K视觉 |
| 边缘服务器 | RK3588 + 8×贡嘎 | 50T,支持20路视频分析 |
五、总结:贡嘎的“降维打击”
在端侧AI芯片普遍“卷”峰值算力时,贡嘎通过系统级创新实现了:
-
性能:100tokens/s相当于高通骁龙8 Gen3的5倍;
-
效率:每token功耗仅为云端GPU的1/20;
-
易用性:1天完成模型迁移,开发者零学习成本。
正如瑞芯微所言:“贡嘎不是要替代SoC,而是让旗舰芯片如虎添翼。”当竞品还在优化7B模型的压缩率时,搭载贡嘎的设备已能流畅运行13B参数的多模态大模型——这或许就是端侧AI的下一个分水岭。











