
一场设备端人工智能的革命悄然降临,你的旧手机即将获得新生。
日前,谷歌宣布全面开源Gemma 3n——这款突破性的多模态AI模型,专为智能手机、平板电脑及笔记本电脑等边缘设备设计,无需依赖云端算力或高速网络连接即可运行。这一发布标志着设备端人工智能迈入全新阶段,将云端级别的多模态能力直接带入用户口袋。
01 技术奇迹,小身材大智慧
Gemma 3n的核心突破在于其前所未有的高效架构设计。该模型采用创新的MatFormer架构(Matryoshka Transformer),其设计灵感源自俄罗斯套娃——在一个较大模型中嵌套多个完全功能的较小模型。这种独特结构使开发者能根据设备硬件能力动态调整模型规模:E2B版本仅需2GB内存,E4B版本也仅需3GB内存即可流畅运行。
尽管参数规模达到惊人的50亿(E2B)和80亿(E4B),Gemma 3n通过三项关键技术突破实现了“瘦身”奇迹:
-
Per-Layer Embeddings (PLE)技术:将大部分参数计算转移至CPU处理,仅核心Transformer权重需加载到加速器内存,内存效率提升显著。
-
KV Cache Sharing机制:针对长音频、视频输入优化,预填充性能较前代Gemma 3 4B提升两倍,大幅缩短首个token生成时间。
-
混合精度量化技术:在移动设备上响应速度提升1.5倍,同时保持更高质量输出。
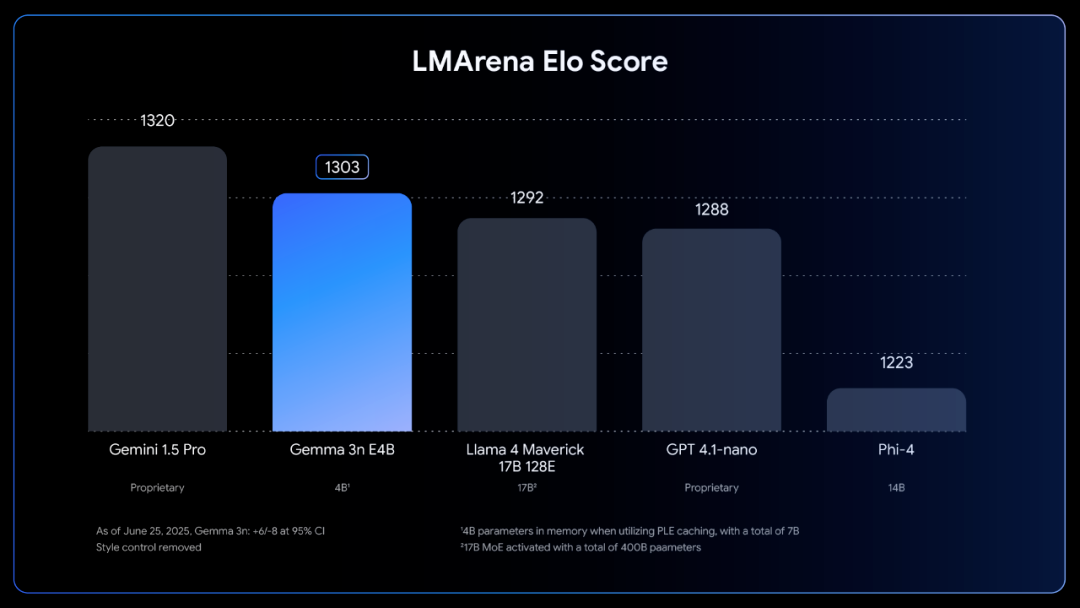 这种架构创新使Gemma 3n E4B版本在LMArena基准测试中得分突破1300分,成为首个在100亿参数以下达到此水准的模型。
这种架构创新使Gemma 3n E4B版本在LMArena基准测试中得分突破1300分,成为首个在100亿参数以下达到此水准的模型。
02 全感官理解,设备端的多模态革命
Gemma 3n原生支持图像、音频、视频、文本四大模态的输入处理,在离线环境下实现真正的多模态理解。
 语音处理方面,模型集成基于通用语音模型(USM)的音频编码器,每160毫秒生成一个语音token。支持30秒长音频片段处理,实现精准的语音转文本及跨语言翻译。早期测试显示,其在英语与西班牙语、法语、意大利语、葡萄牙语等欧洲语言互译中表现优异。
语音处理方面,模型集成基于通用语音模型(USM)的音频编码器,每160毫秒生成一个语音token。支持30秒长音频片段处理,实现精准的语音转文本及跨语言翻译。早期测试显示,其在英语与西班牙语、法语、意大利语、葡萄牙语等欧洲语言互译中表现优异。
视觉能力由全新MobileNet-V5-300M编码器驱动,支持256×256至768×768多分辨率输入。在Google Pixel设备上可实现每秒60帧实时视频分析,处理速度较基线模型提升高达13倍,参数减少46%,内存占用降低75%。
语言支持覆盖140种文本语言,具备35种语言的多模态理解能力。非英语处理能力显著增强,尤其在日语、德语、韩语等语言场景表现突出。
03 开发者生态,开源赋能创新
谷歌此次采取全面开源策略,模型权重及技术文档已在Hugging Face平台开放(https://huggingface.co/collections/google/gemma-3n-685065323f5984ef315c93f4)。开发者可通过多种渠道快速集成:
-
通过Google AI Studio在线体验
-
使用Hugging Face Transformers、llama.cpp、Ollama等主流框架
-
部署到Google AI Edge、MLX等移动开发平台
为激发创新应用,谷歌同步启动Gemma 3n Impact Challenge竞赛,提供15万美元奖金池,鼓励开发者利用其离线多模态能力开发教育、医疗、环保等社会公益项目。
自2024年初Gemma系列发布以来,该家族模型全球下载量已突破1.6亿次,形成强大的开发者生态。此次Gemma 3n的推出将进一步扩展该生态在设备端AI领域的创新边界。
04 隐私与包容,重新定义智能设备
Gemma 3n的离线运行能力解决了AI应用的两大核心痛点:隐私安全与网络依赖。用户敏感数据无需上传云端,在设备端即可完成处理,为医疗、金融等隐私敏感场景提供安全解决方案。
谷歌同时宣布了Gemma家族的专用模型进展:
-
MedGemma:专注健康文本与影像分析,助力医疗AI开发
-
SignGemma:业界最强手语理解模型,支持美国手语(ASL)到英语文本翻译
这些专业模型配合Gemma 3n的通用能力,将推动无障碍通信和专业化AI应用进入新阶段。
边缘计算曾是科技行业的未来承诺,Gemma 3n让它成为今天的现实。当其他科技巨头仍在追求更大参数、更高云消耗的AI模型时,谷歌选择了一条不同的道路:将智能压缩到可以塞入口袋的尺寸。
随着Gemma 3n代码在GitHub和Hugging Face上的释放,一场静默的革命已经开始——从非洲偏远地区的医生使用旧手机进行医学影像分析,到旅行者在无网络环境中实时翻译菜单,人工智能将真正属于每个人,而不仅仅是那些拥有最新设备和最快网络的人。










