
“幻觉率从 78.5% 降到 10.7%,价格打到 0.00022 元/秒,一小时音频转写只花 8 毛钱。”
—— 这是 2025 年 9 月 15 日阿里巴巴通义实验室给整个行业扔下的“三颗雷”。
在过去十二个月里,我们见证了 GPT-4o 把「端到端语音对话」带到消费级市场,也见证了讯飞星火、Kimi-Audio-8B、Seed-ASR 在中文场景轮番刷榜。但当大家还在争论“级联 vs 端到端”谁更可控时,FunAudio-ASR 用一份 Technical Report、两个版本模型、N 个落地场景,直接把“生成式 ASR”拉进了生产级应用时代。
本文将基于官方技术报告、智东西一手评测与钉钉真实业务数据,从算法、数据、工程、商业四根主线,对 FunAudio-ASR 做一次“庖丁解牛”式拆解。读完你不仅能知道它为什么能把幻觉压到 10%,也会明白为什么钉钉敢在 5000 万 B 端用户场景里“全员上线”。
1 幻觉:语音大模型的“阿喀琉斯之踵”
1.1 为什么“听对了”反而“写错了”?
传统 ASR 的误差主要来自声学混淆(听不清),而生成式 ASR 多了一个更致命的敌人——幻觉:模型“听”到了正确的声音,却在 LLM 解码阶段凭空“脑补”出不存在的内容。根本原因是声学 Embedding 与文本 Embedding 仍分布在两个截然不同的流形上,LLM 在自回归生成时会被“带偏”。
通义实验室在 Technical Report 里给出一组内部统计:在 28 段高噪声、远场、带口音的难例音频上,纯端到端方案幻觉率高达 78.5%;其中 40% 的幻觉发生在专业术语,30% 发生在中英文 code-switch,剩下 30% 则是“翻译冲动”——用户说的是英文,模型直接输出中文。
1.2 Context 增强:用 CTC 当“哨兵”,先把 LLM 拉回到语音任务
FunAudio-ASR 的核心创意是“Context-Augmented Seq2Seq”:
-
轻量 CTC 解码器先跑一遍非自回归解码,得到 1-best 粗转写;
-
把粗转写当成“任务提示”拼进 LLM 的输入,告诉模型“你只要做语音识别,别翻译、别脑补”;
-
CTC 输出同时送进 RAG 检索器,动态抽取热词,避免千级术语全部硬塞 Prompt 导致的“定制化衰减”。
这套“哨兵—纠正”机制只增加 3 ms 延迟,却能把幻觉率干到 10.7%,远低于 GPT-4o-Realtime 的 35% 和 Whisper-large-v3 的 42%(官方同硬件、同 28 例难例测试集)。
2 架构:0.7B+7B 的“双脑”设计,兼顾精度与延迟
FunAudio-ASR 提供两个版本:
| 版本 | Audio Encoder | LLM 解码器 | 参数量 | RTF (A10) | 场景 |
|---|---|---|---|---|---|
| 满血版 | 0.7 B | 7 B | 7.7 B | 0.11 | 云端精转 |
| nano 版 | 0.2 B | 0.6 B | 0.8 B | 0.03 | 端侧流式 |
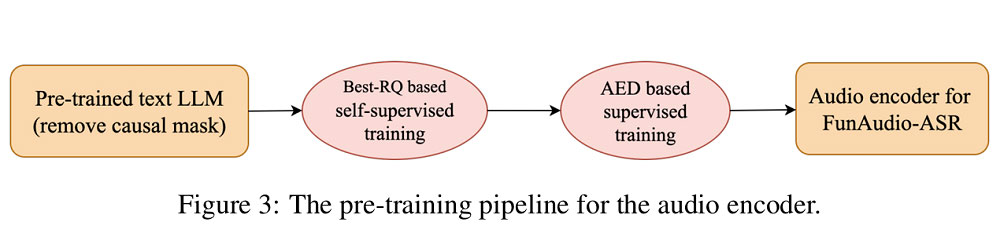 Encoder 均基于 Qwen3 权重初始化,再用数千万小时无监督语音做继续预训练;Adaptor 仅两层 Transformer,负责把 25 ms 帧率、1024-dim 的声学表征压到 4 k 文本空间。LLM 侧支持 4 k 上下文,可吃掉 30 秒语音而不截断。
Encoder 均基于 Qwen3 权重初始化,再用数千万小时无监督语音做继续预训练;Adaptor 仅两层 Transformer,负责把 25 ms 帧率、1024-dim 的声学表征压到 4 k 文本空间。LLM 侧支持 4 k 上下文,可吃掉 30 秒语音而不截断。为了让 nano 版跑得动,团队把 7B 模型做了:
-
8-bit 量化 + AWQ 混合精度,显存占用 2.3 GB;
-
投机解码(speculative decoding)小模型打草稿、大模型做验证,延迟再降 18%;
-
流式前缀 KV-Cache,首包 200 ms,后续每 100 ms 吐一次增量结果。
在钉钉 2025 Q2 的移动端灰测里,nano 版在骁龙 8 Gen3 上跑 1 小时会议只掉电 4%,已接近传统端侧小模型的能耗水平。
3 数据:数千万小时“暴力美学”背后的质量控制
3.1 数据配方
-
无监督:1.2 亿小时原始音频,覆盖中文 65%、英文 20%、日韩 5%、方言 10%;
-
有监督:580 万小时高精度标注,含 200+ 行业垂直语料(法律、医学、畜牧、家装、赛车、半导体等);
-
合成数据:用 CosyVoice 2.0 生成 80 万小时多口音、多噪声、多人称音频,专门喂给 CTC 做“难例特训”。
3.2 五阶段微调
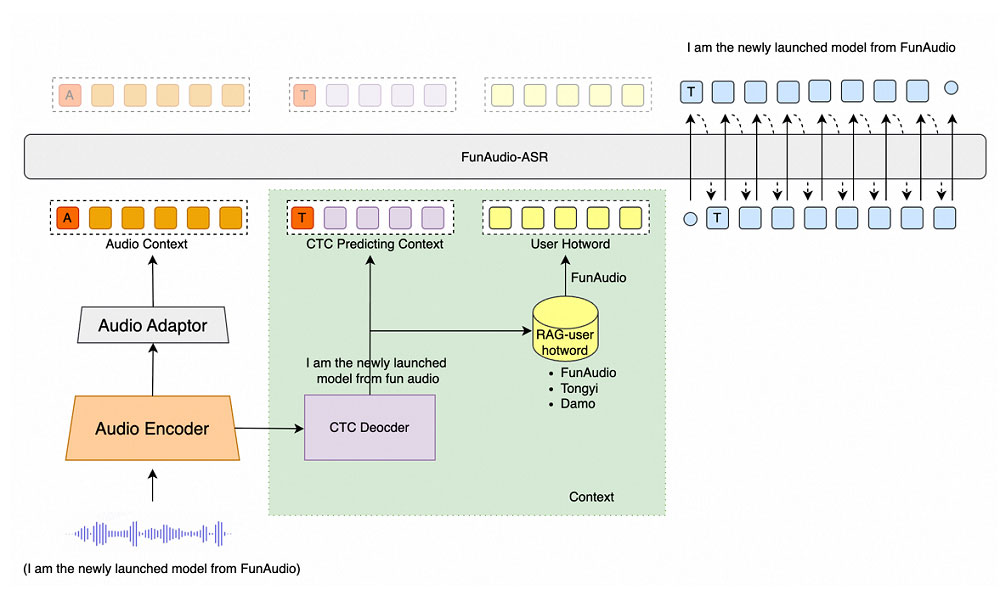 报告里最吸睛的是 SFT 的“五阶段渐进”:
报告里最吸睛的是 SFT 的“五阶段渐进”:-
Adaptor 对齐:冻结 Encoder+LLM,只训 Adaptor,把音频空间硬拉到文本空间;
-
Encoder 解冻:加入 LoRA,学习行业术语;
-
LLM 轻量微调:同样 LoRA,防止灾难性遗忘;
-
全参数微调:用 5 万小时长音频(平均 15 min)教模型吃上下文;
-
CTC 强化:引入 FunRL,用 8 张 A100、一天时间把关键词召回再提 6%。
3.3 仿真+RL 双保险
FunRL 采用 GRPO(Group Relative Policy Optimization),奖励函数四件套:
-
字准:1 – WER;
-
关键词召回:F1;
-
幻觉抑制:对比 CTC 输出,NLI 打分 < 0.8 则扣 0.5;
-
语言一致:出现“中→英”自动翻译就扣 1。
一天训完,模型在 28 段“地狱级”难例上WER 从 18.4% → 9.2%,幻觉句数从 22 → 3。
4 定制:RAG 热词引擎,让“千级”术语不再淹没通用效果
企业级场景最怕“通用模型不认识自家名词”。传统做法是把所有热词拼进 Prompt,但 500 个词以上召回率反而下滑。FunAudio-ASR 的做法是“检索—验证—注入”:
-
离线建库:把企业通讯录、知识库、SKU 名录做成 768-d 向量库;
-
在线检索:用 CTC 1-best 当 query,实时召 Top-K(K=10~20)相关词;
-
动态 Prompt:只把相关词喂给 LLM,无关词全部屏蔽,避免“背景噪音”。
在微积分、有机化学、物理、哲学、人名 5 个领域 1000 个专有名词测试上,FunAudio-ASR 关键词 F1 达到 0.91,比传统“全词 Prompt”方案高 18%,比 Whisper 高 34%。
5 落地:钉钉“AI 听记” 5000 万次调用,成本只有原来的 1/4
5.1 场景矩阵
-
视频会议:实时字幕 + 会后纪要,日均 120 万场会议;
-
AI 硬件:DingTalk A1 投影音响,远场 5 m 识别,唤醒+转写一体化;
-
法务/财务/客服:对公录音质检,支持 10 人连续说话分离;
-
直播同传:B 站、淘宝直播双语字幕,延迟 < 1.5 s。
5.2 成本账本
官方定价 0.00022 元/秒,按一小时音频 3600 s 计算:
-
转写费用:0.79 元;
-
加上分离说话人、时间戳、标点规整,综合成本 < 1 元/小时;
-
钉钉 2025 Q2 调用量 5300 万次,总成本 4200 万元,同比去年使用第三方商用 ASR 节省 1.3 亿元。
5.3 企业私有化
针对金融、政府、医疗的私有化需求,团队给出“一箱即部署”方案:
-
单机 2 × A100 80 GB,可吃 500 并发流;
-
镜像 23 GB,支持 K8s 一键横向扩容;
-
热词库、行业模型、合规敏感词过滤全部本地存储,数据不出域。
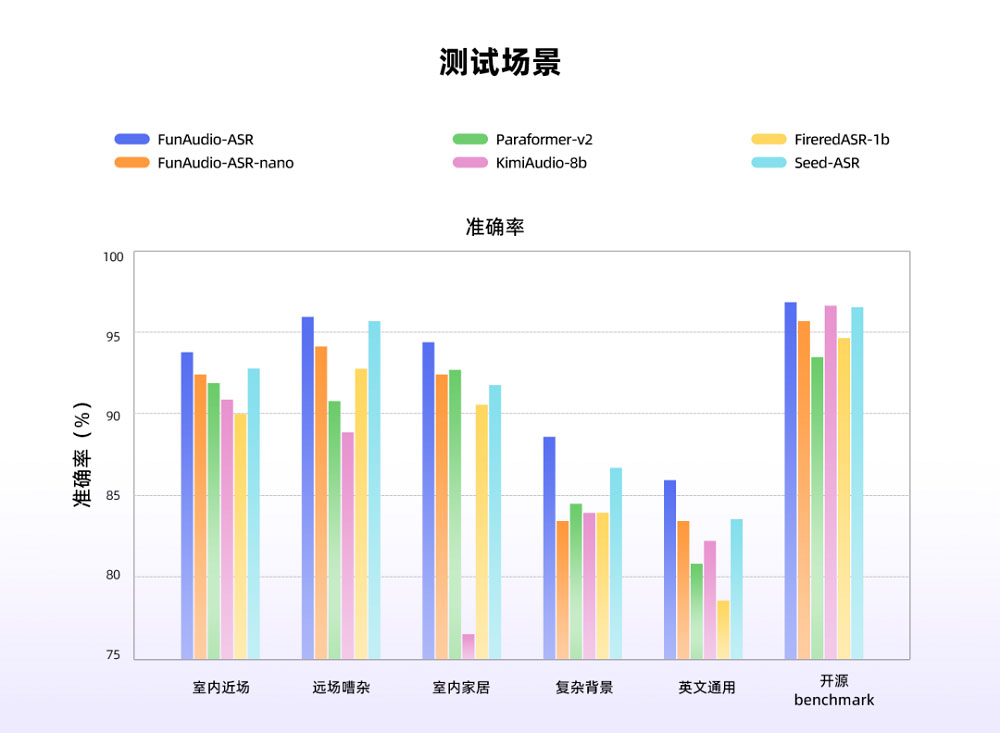
6 横向评测:与 Paraformer-V2、FireredASR-1B、Seed-ASR、KimiAudio-8B 的同场竞技
7 未来 Roadmap:多模态、端侧、Plugin 三部曲
通义实验室在报告最后给出三张“明牌”:
-
2025 Q4 发布 FunAudio-ASR-V2,引入视觉唇部信息,幻觉率再降 3 %,支持 30 % 遮挡场景;
-
2026 Q1 端侧 0.1 B 超小模型,目标 RTF 0.01,唤醒+转写功耗 < 50 mW,面向 TWS、车载;
-
2026 Q2 开放 Plugin 市场,企业可上传自训 LoRA,平台自动做蒸馏、加密、计费,打造“语音 App Store”。
结语:语音识别“最后的战场”不再是“错字率”
FunAudio-ASR 的出现标志着中文语音识别正式步入“大模型”深水区:当 WER 已经卷到 3 % 以内,大家的注意力开始转向“幻觉”“热词”“成本”“端侧”这些更贴近落地的指标。用通义实验室的话说,“ASR 的终极形态不是转写,而是交互入口”。
随着 nano 版下沉到耳机、车机、会议室,满血版接管直播、同传、法庭,FunAudio-ASR 正在让“语音识别”从功能模块升级为“下一代人机交互 OS”。而 0.00022 元/秒的定价,则把最后一道门槛也几乎抹平——对于开发者和企业而言,语音大模型不再是“奢侈品”,而是“水电煤”。
接下来,就看我们如何在如此廉价的语音智能上,长出新的杀手级应用了。











