
在人工智能、边缘计算和移动计算迅猛发展的当下,传统计算架构正面临前所未有的挑战。单一处理器架构已难以满足日益增长的性能、能效和灵活性需求。为应对这一趋势,Arm 公司于日前正式推出了其全新的异构计算平台——Arm Lumex。Lumex 不仅是一次硬件架构的升级,更是 Arm 对未来计算范式的系统性重构,旨在为智能手机、笔记本电脑、汽车、边缘设备等多领域提供统一、高效、可扩展的计算基础。
本文将基于 Arm 官方发布的信息与多方技术解读,全面解析 Lumex 的技术架构、核心组件、性能优势、生态战略及其对未来计算平台的深远影响。
一、Arm Lumex 的诞生背景
1.1 计算需求的多元化
随着 AI 模型规模的指数级增长,传统 CPU 已难以独立承担高负载推理与训练任务。GPU、NPU、DSP 等专用加速器逐渐进入主流计算体系,形成了“异构计算”的新格局。然而,异构计算也带来了新的挑战:不同计算单元之间的协同效率、数据搬运开销、软件栈复杂性、功耗控制等问题日益突出。
1.2 移动与边缘计算的崛起
智能手机、AR/VR 设备、自动驾驶汽车、工业边缘网关等场景对计算性能的需求已接近甚至超越传统 PC。与此同时,这些设备对功耗、散热、体积的限制却更加严苛。如何在“性能”与“能效”之间取得平衡,成为芯片设计的关键难题。
1.3 Arm 的战略转型
作为全球领先的 IP 架构提供商,Arm 意识到仅靠提供 CPU 核心已无法满足未来计算平台的需求。为此,Arm 提出了“Total Compute”战略,强调从系统级角度优化整个计算平台,涵盖 CPU、GPU、NPU、互连、内存、软件栈等多个维度。Lumex 正是这一战略的最新落地成果,标志着 Arm 从“IP 提供商”向“平台解决方案提供商”的转型。
二、Arm Lumex 平台架构详解
 Arm Lumex 并非单一芯片或 IP 核,而是一个可扩展的异构计算平台架构,其核心设计理念是“模块化、可配置、系统级优化”。Lumex 平台由多个关键组件构成,包括:
Arm Lumex 并非单一芯片或 IP 核,而是一个可扩展的异构计算平台架构,其核心设计理念是“模块化、可配置、系统级优化”。Lumex 平台由多个关键组件构成,包括:2.1 Lumex Compute Subsystem(计算子系统)
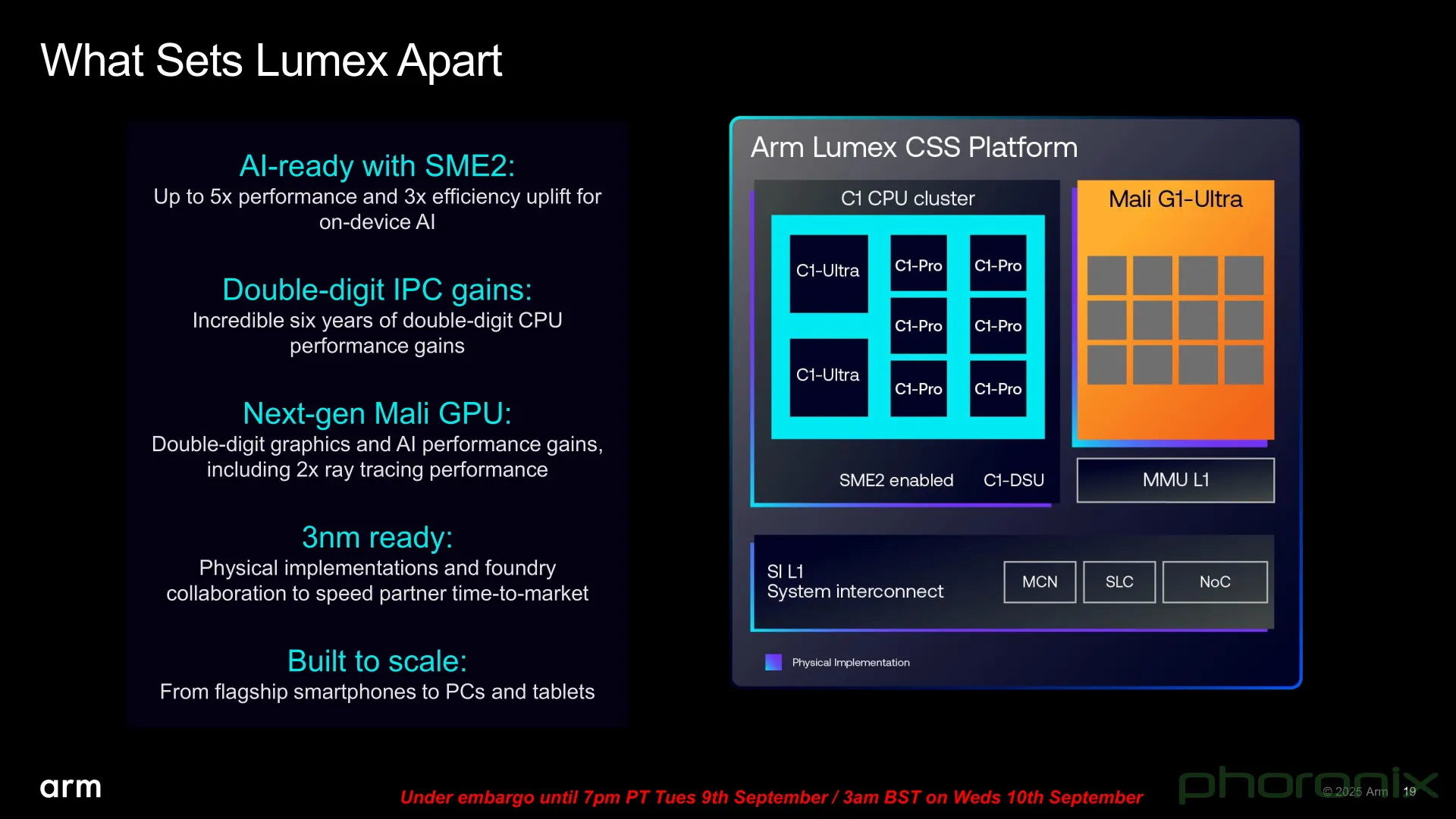 Lumex 的计算子系统是其核心模块,采用多核异构设计,支持灵活配置。其主要特点包括:
Lumex 的计算子系统是其核心模块,采用多核异构设计,支持灵活配置。其主要特点包括:-
多核 CPU 集群:基于 Armv9.2 架构,支持 Cortex-X925、Cortex-A725 与 Cortex-A520 的 big.LITTLE 组合,最高可支持 14 核配置。
-
Arm Immortalis GPU:集成最新一代 Immortalis-G935 GPU,支持光线追踪、可变速率渲染、AI 加速图形处理。
-
Ethos-U NPU:内置 Ethos-U85 NPU,支持 INT8、INT16、FP16 精度,峰值算力达 20 TOPS,适用于边缘 AI 推理。
-
CoreLink CI-700 互连总线:支持高带宽、低延迟的片上通信,优化多核与加速器之间的数据搬运效率。
-
系统级缓存(SLC):高达 32MB 的共享缓存,减少内存访问延迟,提升整体能效。
 2.2 Lumex AI Framework(AI 框架层)
2.2 Lumex AI Framework(AI 框架层)
Lumex 平台内置了 Arm 自研的 AI 框架层,支持主流 AI 框架(如 TensorFlow Lite、ONNX Runtime、PyTorch Mobile)无缝部署。其特点包括:
-
统一 AI 编译器:支持自动图优化、算子融合、内存复用,提升推理效率。
-
异构调度器:根据任务特性动态分配计算资源,实现 CPU+NPU+GPU 的协同加速。
-
量化与压缩工具链:支持模型量化、剪枝、蒸馏,适配边缘设备资源限制。
2.3 Lumex Security Architecture(安全架构)
安全性是 Lumex 平台的重要设计目标之一。其安全架构包括:
-
Arm Confidential Compute Architecture(CCA):支持可信执行环境(TEE)与机密计算,保护用户数据与模型隐私。
-
Memory Tagging Extension(MTE):防止内存越界访问,提升系统稳定性。
-
Secure Boot & Firmware Validation:从芯片启动阶段即确保系统完整性,防止恶意代码注入。
2.4 Lumex Platform C1:首款参考设计
 Arm 基于 Lumex 架构推出了首款参考设计平台——Platform C1,旨在为 OEM 与芯片厂商提供完整的开发基础。Platform C1 的主要参数如下:
Arm 基于 Lumex 架构推出了首款参考设计平台——Platform C1,旨在为 OEM 与芯片厂商提供完整的开发基础。Platform C1 的主要参数如下:| 组件 | 规格 |
|---|---|
| CPU | 1× Cortex-X925 + 3× Cortex-A725 + 4× Cortex-A520 |
| GPU | Immortalis-G935(16 核) |
| NPU | Ethos-U85(20 TOPS) |
| 内存 | LPDDR5X(8533 Mbps) |
| 存储 | UFS 4.1 |
| 制程 | TSMC N3E |
| AI 性能 | 30 TOPS(整型) / 15 TFLOPS(浮点) |
| 功耗 | <8W(典型负载) |
 Platform C1 已被多家头部芯片厂商(如联发科、三星、高通)采用,预计将于 2026 年 Q1 商用落地。
Platform C1 已被多家头部芯片厂商(如联发科、三星、高通)采用,预计将于 2026 年 Q1 商用落地。三、Lumex 的技术优势分析
3.1 异构协同:打破“烟囱式”计算
 传统异构计算平台往往存在“烟囱式”问题:CPU、GPU、NPU 各自为政,数据搬运频繁,协同效率低。Lumex 通过以下方式实现真正的异构协同:
传统异构计算平台往往存在“烟囱式”问题:CPU、GPU、NPU 各自为政,数据搬运频繁,协同效率低。Lumex 通过以下方式实现真正的异构协同:-
统一内存架构(UMA):所有计算单元共享同一物理内存空间,避免数据拷贝。
-
任务级动态调度:AI 框架层可根据任务特性自动选择最优计算单元。
-
低延迟互连:CoreLink CI-700 总线支持 QoS 调度与缓存一致性,提升多核协作效率。
3.2 能效比领先:每瓦性能提升 2.3 倍
根据 Arm 官方数据,Lumex 平台在相同功耗下的 AI 推理性能较上一代平台提升 2.3 倍,主要得益于:
-
NPU 专用加速:Ethos-U85 针对 Transformer、CNN、RNN 等模型深度优化。
-
DVFS 动态调频:根据负载实时调整电压与频率,降低空闲功耗。
-
片上缓存优化:SLC 减少 DDR 访问次数,降低系统级功耗。
 3.3 软件生态成熟:一次开发,多端部署
3.3 软件生态成熟:一次开发,多端部署
Lumex 平台全面支持 Arm 的 KleidiAI 与 KleidiCV 软件库,提供高性能、低延迟的 AI 与计算机视觉原语。开发者可通过以下方式快速部署应用:
-
Android NNAPI / ML Kit:无缝对接 Android 系统 AI 接口。
-
Arm NN / TFLite Delegate:自动调用 NPU 加速,无需手动优化。
-
Unity / Unreal Engine 插件:支持游戏引擎内 AI 推理与图形渲染协同。
四、Lumex 的应用场景展望
4.1 智能手机:AI 拍照与实时翻译
Lumex 平台的高性能 NPU 可支持手机端运行 70 亿参数级大语言模型,实现:
-
实时语音翻译:离线运行多语言模型,延迟 <200ms。
-
AI 拍照增强:基于扩散模型实现夜景降噪、超分、风格迁移。
-
个性化推荐:本地运行推荐模型,保护用户隐私。
4.2 AI PC:轻量级 Copilot 设备
随着 AI PC 概念兴起,Lumex 平台可作为 Windows on Arm 设备的核心计算平台,支持:
-
本地 Copilot 助手:运行 7B 参数模型,支持文档总结、代码生成。
-
AI 图像编辑:Photoshop、Lightroom 等应用可调用 NPU 加速滤镜与修复。
-
视频会议增强:背景虚化、眼神校正、语音降噪等 AI 功能本地运行。
4.3 汽车座舱:多模态交互与感知
Lumex 平台可用于智能座舱域控制器,支持:
-
多屏异显:GPU 支持 4K 多屏输出,满足仪表盘、中控屏、娱乐屏需求。
-
驾驶员监测:NPU 实时运行 DMS 模型,识别疲劳、分心、手势。
-
语音助手:本地运行语音识别与自然语言理解模型,降低云端依赖。
4.4 边缘网关:工业 AI 推理节点
在工业场景中,Lumex 可作为边缘 AI 网关核心平台,支持:
-
设备预测性维护:运行振动分析、温度预测模型。
-
视觉质检:高帧率图像识别缺陷,替代人工巡检。
-
数据脱敏与加密:利用 CCA 实现本地数据加密与模型隔离。
五、Lumex 的战略意义与行业影响
5.1 对 Arm 自身的意义
Lumex 的推出标志着 Arm 从“IP 提供商”向“平台级解决方案商”的转型。通过提供完整的硬件参考设计、软件栈与工具链,Arm 正在构建一个类似“Android 生态”的 AI 计算平台,增强其对下游客户的粘性。
5.2 对芯片厂商的影响
Lumex 为芯片厂商提供了“拎包入住”式的开发平台,显著缩短芯片设计周期。预计未来将涌现一批基于 Lumex 的“AI 原生”SoC,推动中端设备智能化升级。
5.3 对开发者的影响
Lumex 的统一软件栈将降低 AI 应用开发门槛,开发者无需关心底层硬件差异,即可实现“一次开发,多端部署”。这将极大促进 AI 应用在手机、PC、汽车等场景的落地。
5.4 对竞争格局的影响
Lumex 的推出将直接挑战高通、苹果、英伟达等厂商的封闭生态。凭借其开放性与能效优势,Arm 有望在 AI 边缘计算领域重塑竞争格局,成为“AI 时代的 Android”。
六、未来展望:Lumex 2.0 与生态演进
Arm 已透露,Lumex 将在 2026 年推出 Lumex 2.0 平台,重点方向包括:
-
支持 100B 参数级模型:通过稀疏计算与模型压缩技术,实现本地大模型运行。
-
Chiplet 架构支持:支持多芯片互连,构建模块化 AI 计算集群。
-
RISC-V 协同:探索与 RISC-V 核心的混合架构,满足定制化需求。
-
AI 工具链开源:计划开源部分 AI 编译器与调度器,吸引开发者共建生态。
七、结语:Lumex 开启 AI 计算新纪元
Arm Lumex 不仅是一个技术平台,更是 Arm 对未来计算范式的深刻回应。在 AI 与边缘计算席卷全球的当下,Lumex 以其开放、高效、可扩展的特性,为下一代智能设备提供了坚实的计算基石。正如 Android 重新定义了移动互联网,Lumex 有望重塑 AI 时代的计算生态,成为万物智能的“隐形发动机”。
未来已来,Lumex 已至。











