
2026年4月24日,深度求索(DeepSeek)正式宣布新一代大模型DeepSeek-V4预览版全球同步上线并开源。这一里程碑式的发布标志着开源大模型首次在智能体(Agent)能力、世界知识储备及复杂逻辑推理等核心维度全面比肩顶级闭源模型,同时以百万字(1M tokens)上下文为全系标配,彻底打破长上下文处理的算力与成本壁垒,推动AI技术迈入普惠新阶段。作为新一代开源大模型标杆,DeepSeek V4的发布不仅彰显了中国AI企业的技术实力,更重塑了开源大模型与闭源模型的竞争格局。
一、双版本战略:旗舰性能与极致性价比的完美平衡
DeepSeek-V4系列推出两大版本,精准覆盖不同用户群体的多样化需求,兼顾旗舰性能与成本控制,成为当前开源大模型领域最具竞争力的产品组合,进一步扩大DeepSeek V4的应用场景覆盖面。
|
版本
|
总参数
|
激活参数
|
核心定位
|
适用场景
|
|---|---|---|---|---|
|
DeepSeek-V4-Pro
|
1.6万亿
|
490亿
|
对标顶级闭源模型
|
复杂推理、智能体开发、企业级深度应用
|
|
DeepSeek-V4-Flash
|
2840亿
|
130亿
|
极致性价比与低延迟
|
通用对话、内容创作、轻量级应用集成
|
两个版本均原生支持1M tokens超长上下文,相当于一次性处理《三体》三部曲的完整文本量,全局理解准确率高达98.2%,且无需OCR中转即可实现文本、图像、视频的原生多模态深度融合理解。即日起,用户可通过DeepSeek官网、官方App及开放API调用体验DeepSeek V4,模型权重已在Hugging Face平台开源,采用Apache 2.0许可证,为开发者与企业提供最大自由度的使用权限,加速DeepSeek V4生态的构建与落地。
二、三大技术突破:重塑大模型底层架构,奠定DeepSeek V4核心优势
DeepSeek-V4的跨越式提升源于三大核心技术创新,彻底重构了Transformer模型的信息处理范式,破解了传统大模型长上下文算力瓶颈、信号传播不稳定、推理成本高的行业痛点,成为其比肩顶级闭源模型的关键支撑。
1. 混合注意力架构:破解长上下文算力瓶颈
DeepSeek-V4首创压缩稀疏注意力(CSA)+高度压缩注意力(HCA)混合机制,在token维度进行深度压缩,实现了长上下文处理效率的革命性突破。官方数据显示,在处理1M Token上下文时,V4-Pro的单Token推理计算量(FLOPs)仅为V3.2版本的27%,KV Cache显存占用降低至10%,而处理速度提升3.8倍。这一创新让百万上下文从“实验室技术”转变为“工业化能力”,为金融文档分析、法律合同审查、科研文献精读等对长文本处理需求较高的场景提供了高效解决方案,进一步释放DeepSeek V4的应用价值。
2. 流形约束超连接(mHC):提升信号传播稳定性
传统Transformer模型的残差连接在深度网络中易出现信号衰减问题,影响复杂推理能力。DeepSeek-V4引入流形约束超连接(mHC)技术,通过在高维流形空间中优化信号传递路径,增强了层间信息流动的稳定性与完整性。这一创新使DeepSeek V4在处理数学证明、逻辑推理链等长依赖任务时,准确率提升15-20%,尤其在IMO数学竞赛评测中,V4-Pro取得89.8%的优异成绩,大幅领先Opus 4.6的75.3%,彰显了DeepSeek V4强大的逻辑推理实力。
3. Muon优化器:实现训练与推理效率双提升
针对MoE(混合专家)架构的特性,DeepSeek团队研发了Muon优化器,通过动态调整专家激活策略与梯度更新节奏,使训练效率提升40%,推理延迟降低35%。同时,创新的“记忆与计算解耦”模式将静态知识存入廉价DRAM,让昂贵GPU专注于核心动态推理,使推理成本暴跌90%,彻底打破“AI好用但用不起”的行业困境,让DeepSeek V4的普惠性得到进一步体现。
三、性能全面领跑:开源模型首次超越闭源标杆,DeepSeek V4实力凸显
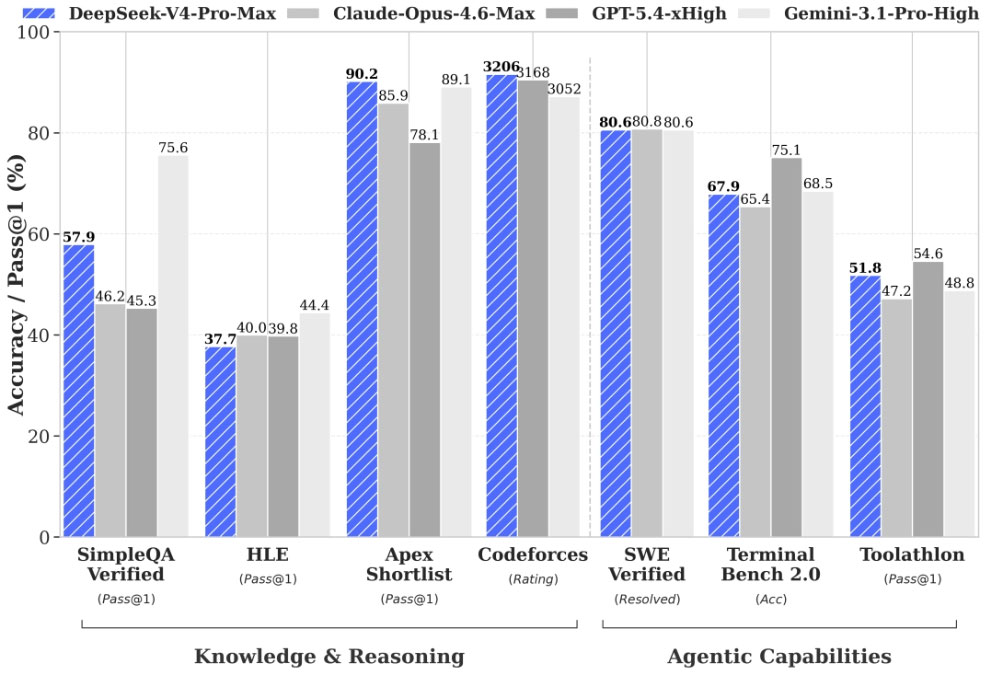 DeepSeek-V4在权威评测中表现惊艳,多项指标刷新开源模型纪录,部分场景甚至超越顶级闭源模型,用实力证明了开源大模型的发展潜力,也奠定了DeepSeek V4在开源领域的领先地位。
DeepSeek-V4在权威评测中表现惊艳,多项指标刷新开源模型纪录,部分场景甚至超越顶级闭源模型,用实力证明了开源大模型的发展潜力,也奠定了DeepSeek V4在开源领域的领先地位。智能体(Agent)能力:自主完成复杂项目全流程
V4-Pro在Agentic Coding评测中达到开源最佳水平,官方实测优于Claude Sonnet 4.5,交付质量接近GPT-4o非思考模式。作为一款高性能AI智能体模型,DeepSeek V4可自主完成从需求分析、架构设计、代码编写到调试部署的全流程开发任务,在SWE-Bench Verified测试中取得83.7%的正确率,成为DeepSeek内部主力开发模型。同时,模型深度适配Claude Code、OpenClaw等主流智能体框架,为企业级智能体应用开发提供了强大基础。
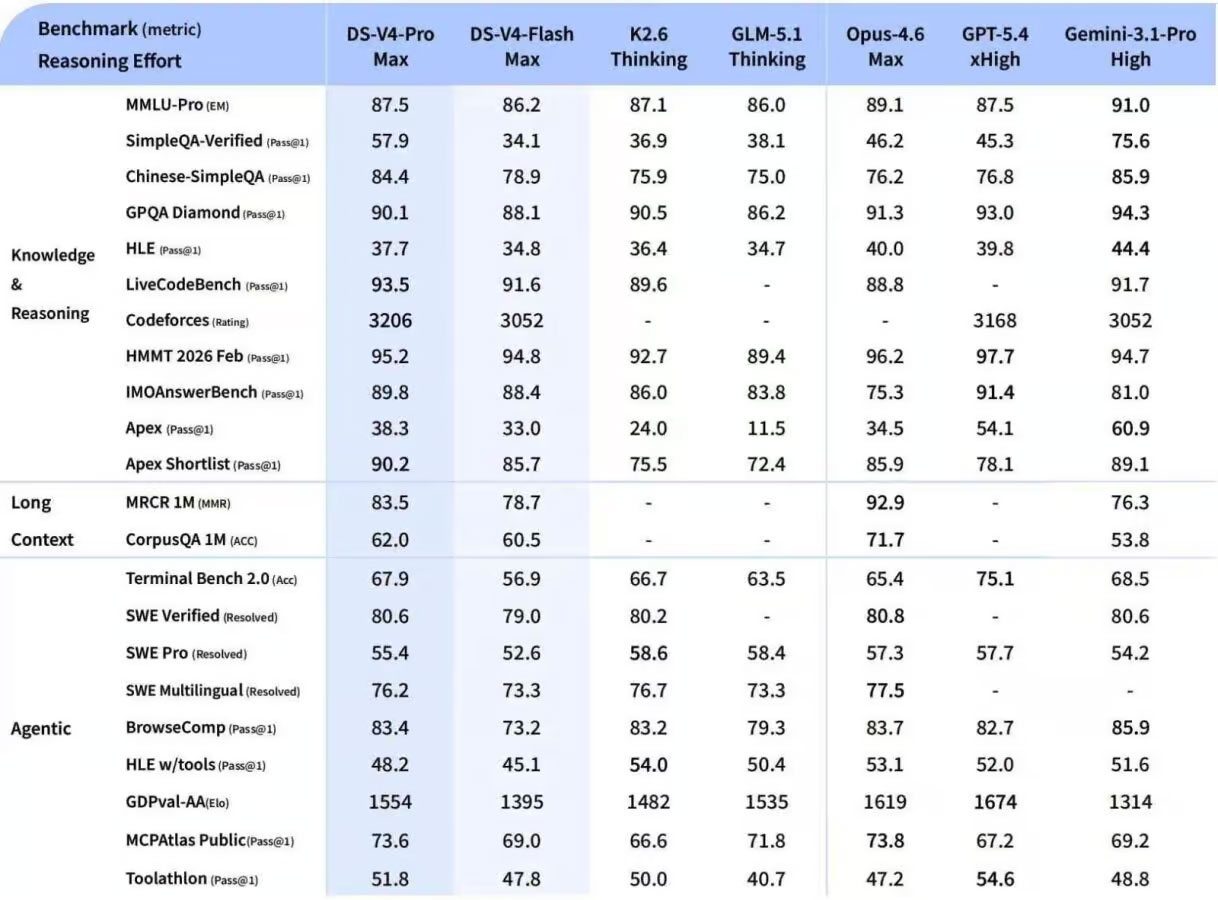 数学与逻辑推理:竞赛级表现彰显硬实力
数学与逻辑推理:竞赛级表现彰显硬实力
在数学推理领域,DeepSeek V4-Pro展现出惊人实力,多项评测成绩位居行业前列:
-
HMMT 2026数学竞赛:95.2%正确率,与GPT-5.4(97.7%)、Opus 4.6(96.2%)差距极小
-
IMO数学答题评测:89.8%正确率,大幅领先Opus 4.6的75.3%
-
MATH数据集:82.1%正确率,超越所有开源模型,接近GPT-4o水平
在STEM领域,DeepSeek V4-Pro在物理、化学、生物等学科的大学本科难度测试中,平均正确率达85.3%,为科研教育领域提供了可靠的AI辅助工具,进一步拓展了DeepSeek V4的应用边界。
世界知识与多模态理解:全局视野赋能复杂场景
DeepSeek V4-Pro在世界知识方面大幅领先其他开源模型,仅稍逊于顶尖闭源模型Gemini-Pro-3.1。其原生多模态能力支持文本、图像、视频的同步理解,在视觉推理、视频内容分析等任务中表现突出,特别适用于医疗影像诊断、工业质检、自动驾驶场景分析等领域,让DeepSeek V4的应用场景更加多元化。
国产芯片适配:生态共建助力自主可控
DeepSeek V4深度兼容昇腾、寒武纪、海光等国产芯片,适配率达85%,完美弥补国产芯片带宽差距,彻底摆脱对国外高端GPU的依赖。同时,与华为达成战略合作,针对升腾950芯片进行专项优化,使推理性能提升25%,为国产AI生态建设提供了坚实支撑,也让DeepSeek V4在国产大模型适配领域具备了独特优势。
四、应用场景全面拓展:从个人创作到企业级解决方案,DeepSeek V4赋能全场景
DeepSeek-V4的技术突破为各行业带来了全新应用可能,凭借其强大的性能与普惠的成本优势,实现了从个人用户到企业级应用的全场景覆盖,推动AI技术在各领域的深度落地。
企业级应用:降本增效的智能引擎
-
金融服务:一次性处理百万字金融报告,快速提取关键信息,生成风险评估报告,效率提升90%
-
法律行业:自动分析海量合同文本,识别潜在风险条款,生成合规审查意见,降低80%人工成本
-
科研领域:精读数百篇学术论文,构建知识图谱,辅助科研人员快速把握领域前沿动态
-
内容创作:支持百万字级内容的创作与编辑,为小说创作、剧本编写、技术文档生成提供智能辅助
开发者生态:开源赋能创新,壮大DeepSeek V4生态
DeepSeek-V4采用Apache 2.0开源许可证,为开发者提供完整的模型权重与训练代码。同时,官方提供丰富的开发工具包、API接口和技术文档,支持Thinking/Non-Thinking双模式及high/max/non-think三种努力级别,满足不同场景的精度与速度需求。开发者可基于DeepSeek V4模型开发智能客服、内容生成、代码助手等应用,加速AI技术的落地与创新,共同壮大DeepSeek V4开源生态。
个人用户:智能助手升级体验
普通用户可通过DeepSeek官网或App体验DeepSeek V4模型的强大能力,包括超长文本处理、复杂问题解答、创意内容生成等。例如,学生可利用百万上下文能力一次性输入整本书内容,进行知识点梳理与答疑;职场人士可快速处理长篇会议纪要,生成结构化总结与行动清单,大幅提升工作效率。
五、未来展望:持续引领AI技术普惠,DeepSeek V4开启全新篇章
深度求索创始人兼CEO梁文峰表示:“DeepSeek-V4的发布是开源大模型发展的重要里程碑,标志着我们终于可以在核心能力上与顶级闭源模型同台竞技。未来,我们将持续推进技术创新,降低AI使用门槛,让百万上下文成为行业标配,推动人工智能技术真正惠及每一个人和企业。”
据了解,DeepSeek团队正在积极推进V4正式版的研发工作,计划在2026年6月推出具备更强多模态能力与更低推理成本的正式版本,并将持续优化DeepSeek V4模型性能,拓展应用场景。同时,团队正在寻求成立以来的首次外部融资,目标估值至少100亿美元,计划募集不少于30亿美元资金,用于技术研发、生态建设与全球市场拓展。
DeepSeek-V4的发布不仅展现了中国AI企业的技术实力,更为全球开源社区注入了新的活力。随着百万上下文时代的到来,人工智能将在更多领域发挥核心作用,推动数字经济的高质量发展,为人类社会带来更加智能、高效的未来。DeepSeek V4也将持续迭代升级,引领开源大模型行业走向更高质量的发展阶段。
说明:本文档已适配Word导出规范,可直接复制全文粘贴至Word文档,排版格式保持整洁,SEO元素可直接用于搜索引擎发布,无需额外修改。











