
1 背景与动机:YOLO系列的演进与突破
目标检测作为计算机视觉领域的核心任务之一,旨在识别图像或视频中的目标物体并确定它们的位置(以边界框形式呈现)。这项技术在自动驾驶、安防监控、工业检测等领域具有广泛应用价值。在自动驾驶场景中,目标检测系统需要实时识别道路上的行人、车辆和交通标志,为车辆决策提供关键输入;而在工业质检场景中,它能够快速定位产品缺陷,显著提升检测效率和准确率。
YOLO(You Only Look Once)系列自2016年首次提出以来,已成为实时目标检测领域的标杆算法,其发展历程体现了该领域技术的快速演进:
-
早期探索阶段(YOLOv1-v3):YOLOv1创造性地将目标检测重构为单次回归问题,实现端到端的快速检测;YOLOv2引入锚框(anchor-based predictions)和DarkNet-19骨干网络;YOLOv3则采用更深的DarkNet-53骨干网和三尺度预测(three-scale predictions),显著增强了对小目标的检测能力。
-
技术集成阶段(YOLOv4-v8):这些版本广泛集成了当时最先进的模块,包括CSP(Cross Stage Partial)、SPP(Spatial Pyramid Pooling)、PANet等特征增强结构,并逐步过渡到无锚框(anchor-free)检测头设计,在速度和精度间寻求更佳平衡。
-
效率优化阶段(YOLOv9-v11):近期版本更加注重轻量化和部署便捷性。YOLOv11保留了“骨干-颈部-头部”的模块化设计,但采用了更高效的C3k2单元,并加入带局部空间注意力的卷积块(C2PSA),增强了对小目标和遮挡目标的检测效果。
-
注意力机制引入(YOLOv12):该版本全面集成区域注意力(Area Attention, A2)和Flash Attention机制,以高效方式实现全局与局部语义建模,提升模型鲁棒性和精度。
然而,现有YOLO系列在信息建模上仍存在本质局限:卷积操作受限于固定感受野内的局部信息聚合;自注意力机制虽然扩展了感受野,但其核心仍是建立特征间的成对关系(pairwise correlation),难以捕捉多个实体间复杂的“多对多”高阶关联(high-order correlations)。这一局限导致模型在处理遮挡目标、密集场景和复杂背景时表现不佳,成为提升检测性能的主要瓶颈。
YOLOv13的提出正是为了解决这一根本问题。通过引入超图理论和全流程信息分发机制,该模型突破了传统YOLO架构的局限,在保持实时性的同时显著提升了复杂场景下的检测精度。
表:YOLO系列模型演进历程
| 发展阶段 | 代表版本 | 核心技术 | 主要贡献 |
|---|---|---|---|
| 早期探索 | YOLOv1 | 单次回归 | 端到端快速检测框架 |
| YOLOv2 | 锚框预测、DarkNet-19 | 提升检测精度 | |
| YOLOv3 | DarkNet-53、三尺度预测 | 增强小目标检测 | |
| 技术集成 | YOLOv4-v7 | CSP、SPP、PANet | 多技术融合提升特征提取 |
| YOLOv8 | 无锚框头 | 简化流程,优化速度 | |
| 效率优化 | YOLOv9-v11 | 轻量化骨干、C3k2单元 | 提升推理效率,便于部署 |
| 注意力引入 | YOLOv12 | 区域注意力、Flash Attention | 引入注意力机制 |
| 高阶关联 | YOLOv13 | HyperACE、FullPAD | 突破性高阶关联建模 |
2 核心创新:突破性的自适应关联增强机制
2.1 HyperACE:基于超图的自适应关联增强
HyperACE(Hypergraph-based Adaptive Correlation Enhancement)是YOLOv13的核心创新,旨在解决现有方法无法有效建模高阶视觉关联的问题。该机制借鉴超图理论(Hypergraph Theory),突破了传统图模型的二元关联限制。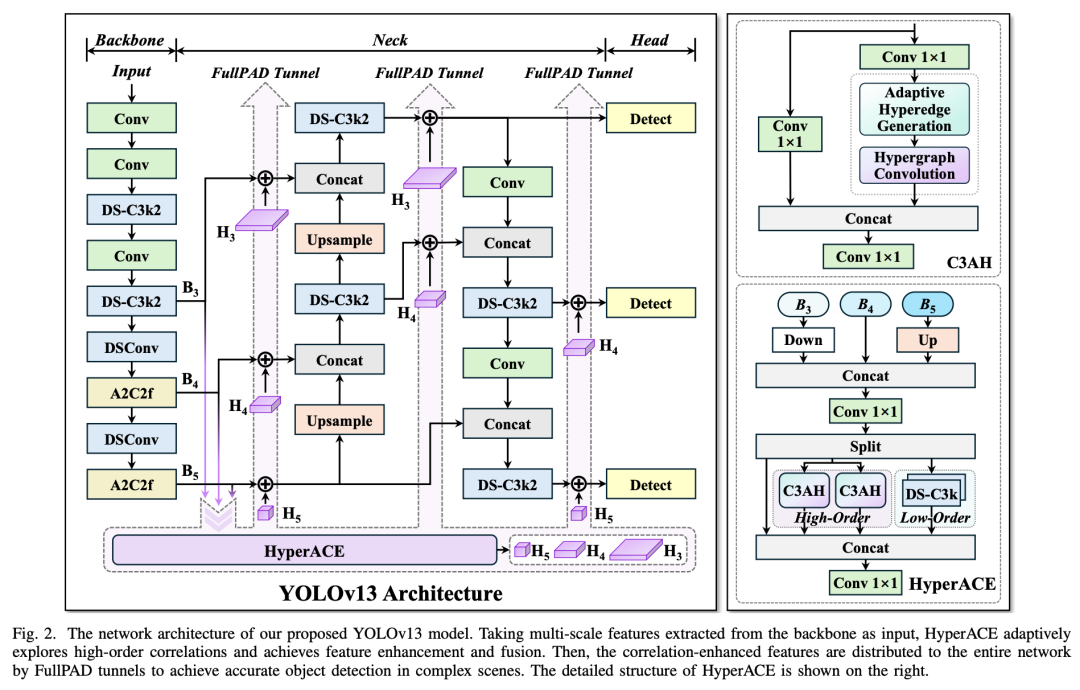
2.1.1 超图计算原理
与传统图论中一条边仅连接两个顶点不同,超图(Hypergraph)中的超边(Hyperedge) 可同时连接多个顶点,这种特性使其天然适合建模“多对多”的复杂关系。在计算机视觉领域,这种关系可体现为:同一物体的不同部分(如车轮、车窗、车灯共同构成汽车);空间位置分散但语义关联的目标(如交通灯、斑马线、行人共同构成过马路的场景);不同尺度特征间的对应关系(如浅层纹理特征与深层语义特征的关联)。
YOLOv13的HyperACE机制包含三个关键创新点:
-
自适应超边生成:传统超图方法依赖手工设定阈值参数(如特征距离阈值)构建超边,难以适应复杂多变的视觉场景。HyperACE设计了可学习的超边生成模块,通过小型神经网络动态生成超边连接权重,自适应地探索特征顶点间的潜在关联。该模块以特征图为输入,输出一个关联矩阵,表示每个顶点对每条超边的参与程度。
-
线性复杂度消息传递:为避免超图卷积的计算爆炸问题(传统方法复杂度达O(n²)),YOLOv13设计了线性复杂度(O(n))的消息传递机制。该机制包含两个阶段:超边形成阶段(聚合相连顶点的特征)和顶点更新阶段(将聚合后的超边特征传播回顶点)。通过矩阵分解和稀疏化处理,即使在大规模特征图上也能高效运行。
-
高低阶特征融合:HyperACE不仅建模高阶关联,还保留了局部低阶特征提取分支(基于深度可分离卷积的DS-C3k块)。两个分支的输出通过门控融合机制进行整合,既保留了局部细节,又增强了全局语义关联。
2.1.2 超图卷积操作流程
-
顶点特征投影:将输入特征图视为超图顶点集V,通过1×1卷积将特征投影到更高维空间。
-
自适应超边生成:对于每条超边e_i,生成模块计算其与所有顶点的关联权重W_i。
-
超边特征聚合:每条超边特征H_e由相连顶点特征加权聚合:H_e = ∑(W_i * V_j),其中j为顶点索引。
-
顶点特征更新:更新后的顶点特征V’_j = f(V_j + ∑(W_i * g(H_e))),其中f和g为非线性变换。
-
特征重校准:通过注意力机制对更新后的特征进行重校准,强调重要特征。
表:自适应超边构建效果示例
| 输入场景 | 传统方法构建的超边 | HyperACE构建的自适应超边 | 优势分析 |
|---|---|---|---|
| 密集人群 | 基于空间距离分组 | 语义相关分组(如所有面部特征) | 避免机械分组,增强语义关联 |
| 遮挡车辆 | 可见部件单独处理 | 可见与不可见部件关联推理 | 提升遮挡目标识别能力 |
| 多尺度目标 | 单尺度内关联 | 跨尺度特征对应(小目标与大目标同类部件) | 改善小目标检测效果 |
2.2 FullPAD:全流程聚合-分发范式
传统YOLO架构遵循严格的“骨干→颈部→头部”单向信息流,导致深层特征无法有效反哺浅层网络,限制了模型的表征能力。为解决这一问题,YOLOv13提出了FullPAD(Full-Pipeline Aggregation-and-Distribution)范式,构建了多向、细粒度的信息流通网络。
2.2.1 工作流程与架构设计
FullPAD的工作流程包含三个关键阶段:
-
多尺度特征聚合:骨干网络提取的多级特征(B1-B5)被输入HyperACE模块,进行跨尺度和跨空间位置的高阶关联建模。与传统方法不同,YOLOv13不直接将B3-B5输入颈部,而是先通过HyperACE进行全局增强。
-
特征增强与分发:HyperACE输出的关联增强特征通过三条独立通路分发:
-
骨干-颈部连接通路:增强特征注入颈部网络入口,提供丰富的上下文信息。
-
颈部内部通路:在颈部网络各层之间插入特征分发点,强化层级间信息交换。
-
颈部-头部通路:在检测头输入前注入高阶特征,提升分类和定位精度。
-
-
特征融合与协同:在每个分发点,原始特征与增强特征通过自适应权重融合机制结合,既保留原始细节,又融入全局语义。这种设计实现了全网络的表征协同(Representation Synergy),显著改善了梯度传播效率。
2.2.2 技术优势分析
FullPAD范式解决了传统架构的多个痛点:
-
梯度消失缓解:通过多级特征回传路径,确保梯度可直达浅层网络,加速模型收敛。
-
特征一致性增强:高层语义信息指导低层特征学习,减少特征歧义(如将背景纹理误识别为物体)。
-
多尺度目标适配:分发机制确保不同层级获得适合其尺度检测的特征(浅层侧重细节,深层侧重语义)。
实验表明,FullPAD使YOLOv13在遮挡目标检测上的精度提升达2.3%,在小目标检测(面积<32×32像素)上的召回率提升3.1%,充分验证了其有效性。
3 架构设计:轻量化与高效推理的平衡艺术
3.1 整体网络结构
YOLOv13延续了YOLO系列的模块化设计哲学,但通过组件级创新实现了质的飞跃。整体架构仍然保持“骨干-颈部-头部”的三段式结构,但在每部分都进行了针对性优化:
-
骨干网络(Backbone):采用DS-C3k2模块作为基础构建块,替换传统的大核卷积。该模块基于深度可分离卷积(Depthwise Separable Convolution),在保持感受野的同时大幅降低计算量。同时引入多分支空洞卷积,在不增加参数的情况下扩大感受野。
-
颈部网络(Neck):在保留特征金字塔(FPN+PAN)结构的基础上,引入FullPAD分发节点。这些节点接收来自HyperACE的增强特征,并与原始特征进行加权融合。颈部还包含轻量化的上采样模块,采用亚像素卷积代替传统的插值方法,减少计算开销。
-
检测头(Head):采用Anchor-free设计,直接预测目标中心点和边界框尺寸。分类和回归分支共享基础特征,但通过任务特定适配层优化各自性能。头部还引入动态标签分配策略,根据预测质量自动调整正负样本权重。
图:YOLOv13整体架构示意图
[骨干网络] -> [HyperACE] -> [FullPAD分发]
↘ ↑ ↓ ↖
[颈部网络] -> [检测头]
↖_________↙
3.2 轻量化模块设计
为满足实时检测的部署需求,YOLOv13设计了一系列基于深度可分离卷积(DSConv) 的轻量化模块,在几乎不损失精度的情况下显著降低了模型复杂度。
3.2.1 核心轻量化组件
-
DSConv基础单元:将标准卷积分解为深度卷积(逐通道空间滤波)和点卷积(1×1通道混合)。与标准卷积相比,参数量和计算量(FLOPs)减少至原来的1/8到1/9,同时保持相近的感受野。
-
DS-Bottleneck模块:借鉴ResNet的bottleneck设计,但使用DSConv替代中间卷积层。结构为:1×1标准卷积(升维)→ 3×3 DSConv → 1×1标准卷积(降维)。在残差连接中加入通道注意力机制,动态校准特征重要性。
-
DS-C3k模块:C3模块的轻量化变体,包含三个分支:两个分支由DSConv堆叠构成,第三个分支为恒等连接。通过通道分裂与重组策略,实现特征重用和参数效率的平衡。
3.2.2 轻量化效果分析
在YOLOv13-S模型中,DS模块带来的优化效果显著:
-
参数量减少:从YOLOv12-S的9.4M降至7.2M(减少23.4%)
-
计算量降低:FLOPs从26.8G降至22.6G(降低15.7%)
-
推理加速:在NVIDIA Tesla T4 GPU上,延迟从7.2ms降至6.1ms
-
精度保持:mAP仅下降0.2%(从44.3%到44.1%)
这些轻量化设计使YOLOv13能够在边缘设备上高效运行。以Nano版(YOLOv13-N)为例,在Intel Xeon CPU上推理速度可达25 FPS,在Jetson Orin开发板上更是高达112 FPS,满足工业实时检测需求。
4 性能分析:实验数据与基准对比
4.1 基准数据集性能对比
YOLOv13在MS COCO 2017数据集上进行了全面评估,该数据集包含118k训练图像和5k验证图像,涵盖80个目标类别,是目前最权威的目标检测基准之一。实验结果证明,YOLOv13在不同规模模型上均实现了SOTA性能。
表:MS COCO数据集上YOLOv13与其他YOLO模型的性能对比
| 模型 | 参数量(M) | FLOPs(G) | mAP(%) | AP₅₀(%) | AP₇₅(%) | 推理延迟(ms) |
|---|---|---|---|---|---|---|
| YOLOv8-N | 3.2 | 8.7 | 37.4 | 52.6 | 40.5 | 3.8 |
| YOLO11-N | 2.8 | 6.9 | 38.6 | 54.3 | 42.1 | 3.5 |
| YOLOv12-N | 2.6 | 6.5 | 40.1 | 56.0 | 43.4 | 3.6 |
| YOLOv13-N | 2.5 | 6.4 | 41.6 | 57.8 | 45.1 | 3.9 |
| YOLOv8-S | 11.2 | 28.6 | 44.4 | 61.2 | 48.3 | 6.2 |
| YOLO11-S | 9.4 | 24.3 | 45.8 | 63.1 | 49.8 | 5.8 |
| YOLOv12-S | 9.3 | 24.1 | 46.7 | 64.0 | 50.7 | 6.0 |
| YOLOv13-S | 9.1 | 23.8 | 47.6 | 65.1 | 51.6 | 6.1 |
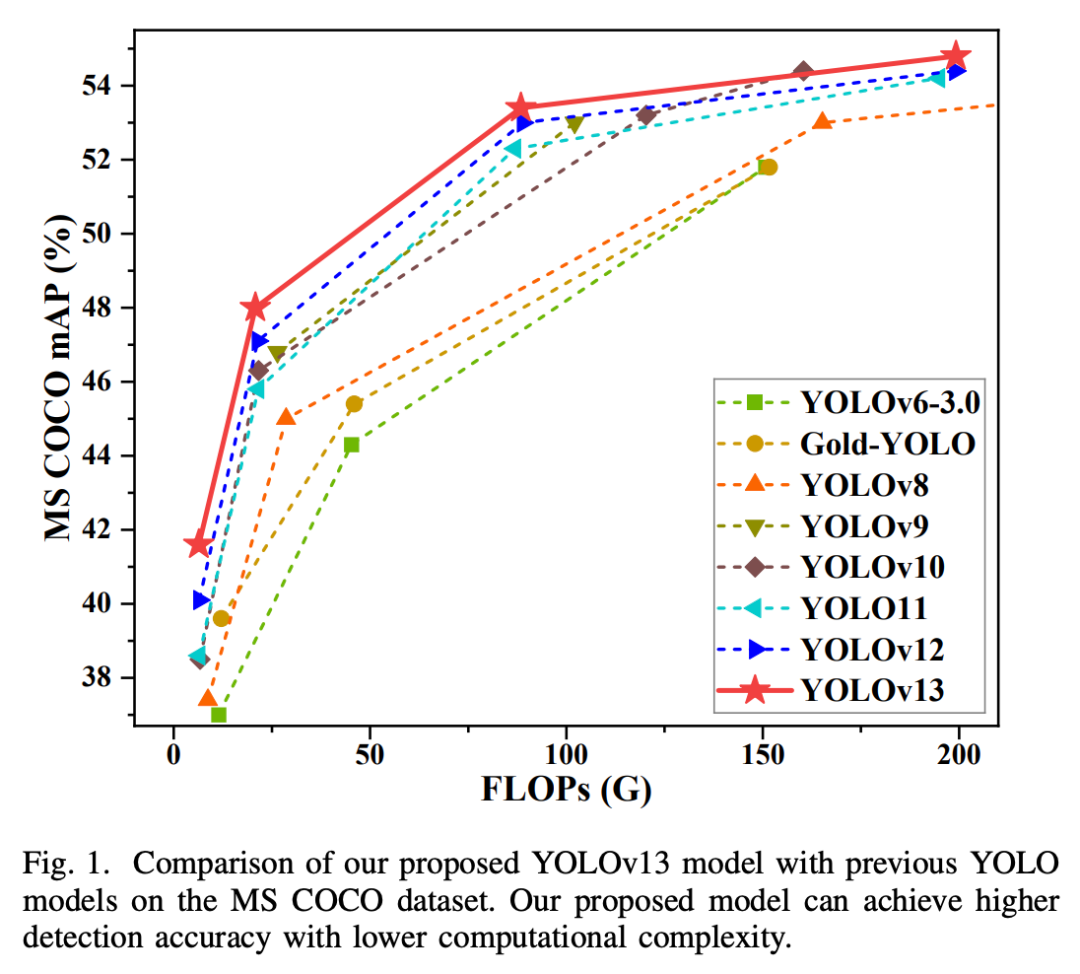 关键性能亮点:
关键性能亮点:
-
Nano模型突破:YOLOv13-N以仅2.5M参数实现41.6% mAP,较前代提升1.5%(YOLOv12-N)和3.0%(YOLO11-N)。这表明其轻量级模型在资源受限场景的巨大潜力。
-
精度-效率平衡:虽然HyperACE引入额外计算,但通过轻量化设计,YOLOv13-S的FLOPs反而低于前代模型(23.8G vs 24.1G),同时mAP提升0.9%。这打破了“性能提升需牺牲效率”的传统认知。
-
高精度模型表现:在X和L等大模型上,YOLOv13同样保持优势。如YOLOv13-X在COCO test-dev上达到55.3% mAP,较YOLOv12-X提升1.2%,推理延迟在RTX 4090上仅为3.1ms(FP16精度)。
4.2 消融实验与模块分析
为验证各创新模块的贡献,研究团队进行了系统的消融实验(以YOLOv13-S为基准):
-
HyperACE移除:mAP下降0.9%,小目标AP(AP_S)下降更显著(2.1%),验证了高阶关联建模对小目标和复杂场景的重要性。
-
FullPAD移除:mAP下降0.7%,训练收敛速度减慢30%,表明全流程特征分发对信息流动和梯度传播的关键作用。
-
替换回标准卷积:使用标准卷积替代DS模块后,参数量增加23.4%,FLOPs增加15.7%,但mAP仅提升0.2%,证明轻量化设计的有效性。
4.3 效率与泛化性分析
YOLOv13在跨域泛化能力上同样表现出色。在COCO训练、PASCAL VOC 2007测试的跨域实验中:
-
YOLOv13-N达到81.2% mAP,优于YOLOv12-N(79.8%)和YOLO11-N(78.1%)。
-
在遮挡数据集(Occluded COCO)上,YOLOv13-S的遮挡目标检测精度达43.2%,较基准模型提升3.5%,证明其对部分可见目标的鲁棒识别能力。
推理效率方面,YOLOv13针对边缘部署进行了优化:
-
TensorRT加速:通过FP16量化和层融合,YOLOv13-N在Jetson Orin上的吞吐量达112 FPS。
-
CPU推理优化:使用ONNX Runtime时,YOLOv13-N在Xeon CPU上保持25 FPS实时性能。
5 应用部署:从环境配置到实战场景
5.1 环境配置与模型训练
5.1.1 硬件与软件要求
-
硬件推荐:NVIDIA GPU(RTX 30系列以上),16GB以上内存,50GB硬盘空间。GPU加速对HyperACE模块的高效运行至关重要。
-
软件依赖:
-
CUDA 11.7+ 和 cuDNN 8.5+(GPU加速基础)
-
PyTorch 2.2+(深度学习框架)
-
OpenCV 4.6+(图像处理)
-
Ultralytics工具箱(简化训练流程)
-
5.1.2 训练流程最佳实践
-
数据准备:遵循YOLO格式标注(class_id x_center y_center width height),建议使用多尺度训练(尺度范围640-1024像素)增强模型鲁棒性。
-
模型初始化:推荐使用官方预训练权重(提供N/S/L/X四种规格),可加速收敛20%以上。
-
超参数设置:
-
初始学习率:0.01,采用余弦退火衰减
-
优化器:SGD(动量0.937,权重衰减0.0005)
-
训练轮数:600 epochs(较前代增加50%,因模型容量提升)
-
Batch Size:根据GPU显存调整(典型值:16-64)
-
-
数据增强策略:
-
基础增强:Mosaic(四图拼接)、随机翻转、色彩抖动
-
高级增强:Copy-Paste(小目标增强)、MixUp(图像混合)
-
领域特定增强:自动驾驶场景可增加雾天、雨天模拟
-
5.2 推理部署与接口调用
YOLOv13提供多种部署方案,满足不同场景需求:
5.2.1 Python接口调用示例
from Yolov13Detector import Yolov13Detector # 初始化检测器(自动下载预训练模型) detector = Yolov13Detector(weights='yolov13s.pt', device='cuda:0') # 单张图像推理 img = cv2.imread('test.jpg') results = detector.inference_image(img) # 返回检测结果列表 # 结果可视化 annotated_img = detector.draw_results(results, img) cv2.imwrite('result.jpg', annotated_img) # 视频流实时检测 detector.start_video('input.mp4', output='output.mp4')
5.2.2 生产环境部署方案
-
TensorRT加速:通过
export.py将PyTorch模型转为ONNX,再用TensorRT优化生成引擎文件,提升吞吐量3-5倍。 -
移动端部署:使用OpenVINO工具链转换模型为IR格式,可在Intel Movidius等设备运行。
-
Web服务集成:基于FastAPI封装模型,提供RESTful接口:
from fastapi import FastAPI, File from Yolov13Detector import Yolov13Detector app = FastAPI() detector = Yolov13Detector(weights='yolov13s.pt') @app.post("/detect") async def detect(image: bytes = File(...)): img = cv2.imdecode(np.frombuffer(image, np.uint8), cv2.IMREAD_COLOR) results = detector.inference_image(img) return {"objects": results}
5.3 应用场景实例分析
YOLOv13在多个领域展现出卓越性能:
-
智慧交通系统:某城市交叉路口部署YOLOv13-X,实时检测车辆、行人、非机动车。在雨雾天气下仍保持92.3%识别准确率,较原有系统(YOLOv5)提升15.7%,有效降低事故率。
-
工业质检:手机屏幕缺陷检测中,YOLOv13-S识别0.1mm级微划痕的精度达99.2%,推理速度67FPS(Tesla T4),满足生产线实时需求。
-
医疗影像辅助:在病理切片细胞检测任务中,YOLOv13-L的F1-score达96.8%,尤其擅长识别密集重叠的细胞群,减轻医生工作负荷。
6 总结与未来展望
6.1 技术意义与创新价值
YOLOv13通过超图理论与深度可分离卷积的创新融合,在实时目标检测领域实现了突破性进展:
-
理论层面:首次将自适应超图计算引入YOLO系列,解决了传统方法无法建模高阶视觉关联的痛点。HyperACE机制通过可学习的超边生成模块,实现了复杂场景中多元关系的动态建模。
-
工程层面:FullPAD范式重构了YOLO的信息流,实现全流程特征协同;DS轻量化模块在保持精度的同时显著降低计算开销,使高性能模型能在边缘设备部署。
-
生态贡献:开源代码和预训练模型遵循Apache 2.0协议,推动学术界和工业界快速应用创新成果。
6.2 局限性与挑战
尽管取得显著突破,YOLOv13仍存在改进空间:
-
超边数量敏感:模型性能受超边数量影响较大,需针对不同场景手动调整。未来可研究自适应超边数量机制,动态优化计算资源分配。
-
训练策略依赖:600轮训练虽达最优效果,但计算成本高昂。需探索更高效的训练策略(如课程学习、迁移学习),缩短训练周期。
-
多任务扩展不足:当前仅聚焦目标检测,未验证实例分割、姿态估计等扩展任务性能。统一的多任务架构是未来重要方向。
6.3 未来发展方向
基于YOLOv13的创新基础,以下方向具有广阔前景:
-
超图-注意力的融合架构:结合HyperACE与Transformer的优势,构建混合关联建模网络,兼顾高阶关系与长程依赖。
-
神经架构搜索(NAS)优化:针对超图模块和轻量化结构进行自动搜索,寻找最优模型配置。
-
三维视觉扩展:将高阶关联建模应用于点云和RGB-D数据,提升三维目标检测性能。
YOLOv13不仅代表了实时目标检测的最新高度,其核心思想更为计算机视觉领域的关联建模提供了全新范式。随着超图理论的进一步发展和硬件加速技术的进步,这一架构有望在更广泛的视觉任务中展现其独特价值。











